
1. 2025年の会話型音声AI
LLMは優れた会話能力を持っています。
ChatGPTやClaudeとの自由な対話を経験したことがある方なら、LLMとの会話が非常に自然で、幅広い用途に役立つことを直感的に理解できるでしょう。
また、LLMは非構造化情報を構造化データに変換することも得意としています。[1]
新しい音声AIエージェントは、LLMのこれら2つの能力 - 会話能力と、非構造化データから構造を抽出する能力 - を活用して、新しい種類のユーザー体験を生み出しています。
[1] ここでは、一部のLLMの「構造化出力」機能という狭い意味ではなく、より広い意味で使用しています。
音声AIは今日、幅広いビジネスコンテキストで展開されています。例えば:
- 医療機関での診察前の患者データ収集
- インバウンドセールスリードのフォローアップ
- コールセンター業務の増加する種類のタスク処理
- 企業間のスケジュール調整とロジスティクス
- ほぼすべての種類の小規模ビジネスの電話応対
消費者向けでは、会話型音声(および映像)AIもソーシャルアプリケーションやゲームに進出し始めています。また、開発者たちは個人的な音声AIプロジェクトや実験をGitHubやソーシャルメディアで日々共有しています。
2. このガイドについて
このガイドは、音声AI技術の最新状況のスナップショットです。[2]
本番環境で使用可能な音声エージェントの構築は複雑です。多くの要素をゼロから実装するのは容易ではありません。音声AIアプリを構築する場合、このドキュメントで説明する多くの機能についてフレームワークに依存することになるでしょう。しかし、パーツをすべて自分で作るにせよ、そうでないにせよ、それらがどのように組み合わさるかを理解することは有用だと考えています。
このガイドは、Sean DuBoisのオープンソースブックWebRTC For the Curiousから直接インスピレーションを得ています。この本は、最初にリリースされてから4年間、多くの開発者がWebRTCを習得する助けとなってきました。[3]
このドキュメントの音声AIコード例では、Pipecatオープンソースフレームワークを使用しています。PipecatはリアルタイムAIのためのベンダー中立なエージェントレイヤーです。[4] このドキュメントでPipecatを使用した理由は以下の通りです:
- 私たちは毎日これを使って開発し、メンテナンスを支援しているので、よく知っているからです!
- PipecatはNVIDIA、Google、そして何百ものスタートアップがコードベースを活用・貢献している、現在最も広く使用されている音声AIフレームワークだからです。
このドキュメントでは、特定の商用製品やサービスを推奨するのではなく、一般的なアドバイスを提供するよう努めています。特定のベンダーについて言及する場合は、音声AI開発者の大多数が使用しているからです。
それでは始めましょう…
[2] このガイドは元々2025年2月のAIエンジニアリングサミットのために書かれました。4月初めに更新を行いました。
[3] webrtcforthecurious.com — WebRTCは音声AIに関連しており、後のWebSocketsとWebRTCセクションで説明します。
[4] Pipecatには50以上のAIモデルとサービスの統合機能があり、ターン検出や割り込み処理などの最先端の実装も含まれています。WebSocket、WebRTC、HTTP、電話を使用してユーザーと通信するコードをPipecatで書くことができます。Twilio、Telnyx、LiveKit、Daily、その他のインフラストラクチャプラットフォーム用のトランスポート実装も含まれています。JavaScript、React、iOS、Android、C++用のクライアントサイドPipecat SDKもあります。
3. 基本的な会話AIループ
音声AIエージェントの基本的な「仕事」は、人間の発話を聞き、有用な方法で応答し、そのシーケンスを繰り返すことです。
現在の本番環境の音声エージェントは、ほぼすべて非常に似通ったアーキテクチャを持っています。音声エージェントプログラムはクラウドで実行され、音声対音声のループをオーケストレーションします。エージェントプログラムは複数のAIモデルを使用し、一部はエージェントにローカルで実行され、一部はAPIを介してアクセスされます。また、エージェントプログラムはLLMのファンクションコーリングまたは構造化出力を使用してバックエンドシステムと統合します。
- 音声はユーザーのデバイスのマイクで取得され、エンコードされ、クラウドで実行されている音声エージェントプログラムにネットワーク経由で送信されます。
- 入力音声は、LLMのテキスト入力を作成するために文字起こしされます。
- テキストはコンテキスト — プロンプト — にまとめられ、LLMで推論が実行されます。推論出力は、エージェントプログラムのロジックによってフィルタリングまたは変換されることがあります。[5]
- 出力テキストは音声出力を作成するためにテキスト音声合成モデルに送信されます。
- 音声出力はユーザーに送り返されます。
音声エージェントプログラムがクラウドで実行され、テキスト音声合成、LLM、音声認識の処理もクラウドで行われていることにお気づきでしょう。長期的には、より多くのAIワークロードがデバイス上で実行されるようになると予想しています。しかし、今日の本番環境の音声AIは非常にクラウド中心です。その理由は2つあります:
- 音声AIエージェントは、複雑なワークフローを低レイテンシーで確実に実行するために、利用可能な最高のAIモデルを使用する必要があります。エンドユーザーのデバイスには、最高のSTT、LLM、TTSモデルを許容可能なレイテンシーで実行するのに十分なAI計算能力がまだありません。
- 今日の商用音声AIエージェントの大多数は、電話を通じてユーザーと通信しています。電話の場合、エンドユーザーのデバイス — 少なくとも、コードを実行できるデバイス — は存在しません!
このエージェントオーケストレーションの世界に深く潜り込んで、以下のような質問に答えていきましょう:
- 音声AIエージェントにはどのLLMが最適ですか?
- 長時間のセッション中に会話のコンテキストをどのように管理しますか?
- 音声エージェントを既存のバックエンドシステムにどのように接続しますか?[7]
- 音声エージェントがうまく機能しているかどうかをどのように判断しますか?

今日のほぼすべての本番環境の音声AIエージェントのアーキテクチャ
[5] 例えば、一般的なLLMのエラーや安全性の問題を検出するためです。
[6] 深く掘り下げましょう — 編集者より
[7] 例えば、CRM、独自のナレッジベース、コールセンターシステムなど。
4. コア技術とベストプラクティス
4.1. レイテンシー
音声エージェントの構築は、他のAIエンジニアリングと多くの点で似ています。テキストベースのマルチターンAIエージェントの構築経験がある場合、その分野での経験の多くは音声でも役立つでしょう。
大きな違いはレイテンシーです。
人間は通常の会話で素早い応答を期待します。一般的な応答時間は500ミリ秒です。長い間を置くと不自然に感じます。
音声AIエージェントを構築している場合、エンドユーザーの視点からレイテンシーを正確に測定する方法を学ぶ価値があります。
AIプラットフォームが引用するレイテンシーは、真の「音声対音声」の測定値ではないことがよくあります。これは一般的に悪意があるわけではありません。プロバイダー側から見ると、レイテンシーを測定する簡単な方法は推論時間を測定することです。そのため、プロバイダーはそのようにレイテンシーを考えるようになります。しかし、このサーバーサイドの視点では、音声処理、フレーズエンドポイントの遅延、ネットワーク転送、オペレーティングシステムのオーバーヘッドは考慮されません。
音声対音声のレイテンシーを手動で測定するのは簡単です。
会話を録音し、その録音をオーディオエディタにロードし、音声波形を見て、ユーザーの発話の終わりからLLMの発話の始まりまでを測定するだけです。
本番環境で会話型音声アプリケーションを構築する場合、このようにレイテンシーの数値を時々サニティチェックすることは価値があります。これらのテストを行う際にネットワークパケットロスとジッターをシミュレートすると、さらにボーナスポイントです!
真の音声対音声レイテンシーをプログラムで測定するのは難しいです。レイテンシーの一部はオペレーティングシステムの深部で発生します。そのため、ほとんどの観測ツールは最初の(音声)バイトまでの時間だけを測定します。これは音声対音声の総レイテンシーの妥当な代用となりますが、フレーズエンドポイントの変動やネットワークの往復時間など、測定していないものが問題になる可能性があることに注意してください。
会話型AIアプリケーションを構築している場合、800ミリ秒の音声対音声レイテンシーは良い目標となります。以下は、ユーザーのマイクからクラウドを経由して戻ってくるまでの音声対音声の往復の内訳です。これらの数値は一般的なもので、合計は約1秒です。800ミリ秒は今日のLLMでは達成が難しいですが、不可能ではありません!
| 段階 | 時間 (ミリ秒) |
|---|---|
| macOSマイク入力 | 40 |
| opusエンコーディング | 21 |
| ネットワークスタックと転送 | 10 |
| パケット処理 | 2 |
| ジッターバッファ | 40 |
| opusデコーディング | 1 |
| 文字起こしとエンドポイント検出 | 300 |
| LLM TTFB | 350 |
| 文章集約 | 20 |
| TTS TTFB | 120 |
| opusエンコーディング | 21 |
| パケット処理 | 2 |
| ネットワークスタックと転送 | 10 |
| ジッターバッファ | 40 |
| opusデコーディング | 1 |
| macOSスピーカー出力 | 15 |
| 合計ミリ秒 | 993 |
音声対音声の会話の往復 — レイテンシーの内訳
すべてのモデルを同じGPU対応クラスタ内でホストし、スループットではなくレイテンシーのためにすべてのモデルを最適化することで、500ミリ秒の音声対音声レイテンシーを達成するPipecatエージェントを実証しています。このアプローチは今日ではあまり使用されていません。モデルのホスティングは高価です。また、GPT-4oやGeminiなどの最高の独自モデルと比べて、オープンウェイトLLMは音声AI用に使用されることが少なくなっています。LLMについては次のセクションで説明します。
音声のユースケースではレイテンシーが非常に重要なため、このガイド全体を通してレイテンシーについて頻繁に取り上げることになります。

4.2. 音声用途のLLM
GPT-4 in March 2023のリリースは、現在の音声AIの時代を切り開きました。GPT-4は、柔軟なマルチターン会話を維持し、必要な作業を正確に実行できる最初のLLMでした。今日、GPT-4の後継者 – GPT-4o – は、コンバーショナル音声AIのドメインで依然としてドメインを占めています。
いくつかの他のモデルは、音声AIにとって重要なことについて、元のGPT-4と同じか、それ以上です。
- インタラクティブな音声会話に対する低いレイテンシー。
- 良い命令の後続性.[8]
- 信頼性のある機能呼び出し.[9]
- 幻覚と他の不適切な応答の低レート。
- 性格とトーン。
- コスト。
[8] モデルに特定のことをさせるのはどれくらい簡単ですか?
[9] 音声AIエージェントは、機能呼び出しに大きく依存しています。
しかし、今日のGPT-4oは、元のGPT-4よりも優れています!特に命令の後続性、機能呼び出し、幻覚の低レートで。
音声AIのユースケースは、その分野で一般的に意味があるため、一般的に最良の可用モデルを使用することが一般的に意味があります。 いつかこれは変わるでしょうが、それはまだ真実ではありません。
私たちは、GoogleのGemini 2.0 Flashが2月6日にリリースされたことを期待しています。Gemini 2.0 Flashは、命令の後続性と機能呼び出しにおいてGPT-4oと同等で、積極的な価格設定がされています。
4.2.1 LLM Latency
Claude Sonnet 3.5の現在のバージョンは、音声AIにとって非常に優れた選択肢ですが、推論レイテンシー(最初のトークンまでの時間)がAnthropicの優先事項ではないため、使用できません。Claude Sonnetの中央レイテンシーは、通常GPT-4oとGemini Flashの2倍で、はるかに大きなP95スプレッドもあります。
| Model | Median TTFT (ms) | P95 TTFT (ms) |
|---|---|---|
| GPT-4o (OpenAI) | 510 | 1,360 |
| Claude Sonnet 3.5 (Anthropic) | 840 | 1,960 |
| Gemini 2.0 Flash (Google) | 460 | 1,610 |
OpenAI、Anthropic、およびGoogle APIのTTFT時間測定 – 2025年2月
経験則によると:LLMの最初のトークン時間が500ミリ秒以下であれば、ほとんどの音声AIユースケースにとって十分です。GPT-4oのTTFTは通常400-500ミリ秒です。Gemini Flashは似ています。
GPT-4o miniはGPT-4oより速くないことに注意してください。これは一般的な期待とは異なり、小さなモデルは大きなモデルより速いと考えられることが多いためです。
4.2.2 Cost comparison
推論コストは定期的に低下しており、急速に低下しています。そのため、一般的にLLMコストは、どのLLMを使用するかを選択する際の最も重要な要因ではありません。Gemini 2.0 Flashの新しい価格設定は、GPT-4oと比較して10倍のコスト削減を提供しています。私たちは、この影響が音声AIのエンジンランドに与える影響を見てみます。
| Model | 3分間の会話 | 10分間の会話 | 30分間の会話 |
|---|---|---|---|
| GPT-4o (OpenAI) | $0.009 | $0.08 | $0.75 |
| Claude Sonnet 3.5 (Anthropic) | $0.012 | $0.11 | $0.90 |
| Gemini 2.0 Flash (Google) | $0.0004 | $0.004 | $0.03 |
セッションコストは、セッションの長さに比例して超線形に増加します。30分間のセッションは、3分間のセッションの約100倍の高価です。キャッシュ、コンテキスト要約、その他の手法を使用して長いセッションのコストを削減できます。
セッションの長さに応じてコストが超線形的に増加することに注意してください。セッション中にコンテキストをトリミングまたは要約しない限り、長いセッションではコストが問題になります。これは特に音声対音声モデルで顕著です(以下を参照)。
コンテキストの成長の数学的性質により、音声会話の1分あたりのコストを正確に把握するのは難しくなっています。さらに、APIプロバイダーはトークンキャッシングを提供するようになってきており、これはコストを相殺し(そしてレイテンシーを削減)できますが、異なるユースケースのコスト見積もりの複雑さを増加させます。
OpenAI Realtime APIの自動トークンキャッシングは特に優れています。他のプラットフォームも同様にシンプルで透明性のあるキャッシングの実装を検討することを推奨します。[10]
私たちはOpenAI Realtime API用の計算機を作成しました。これは、キャッシングを考慮に入れて、セッションの長さに応じてコストがどのようにスケールするかを示しています。
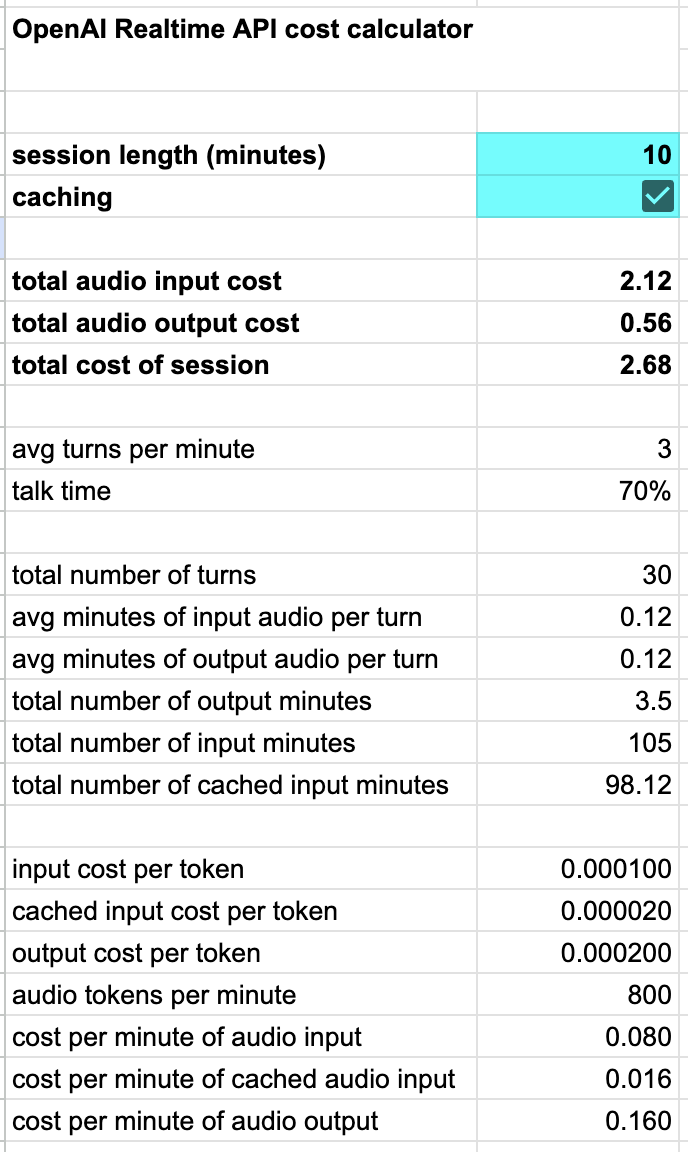
OpenAI Realtime APIコスト計算機
[10] お知らせ: 新しいRealtimeAPI音声とキャッシュ価格設定
4.2.3 オープンソース / オープンウェイト
MetaのLlama 3.3および4.0オープンウェイトモデルは、ベンチマークにおいて元のGPT-4よりも優れたパフォーマンスを示しています。しかし、LLMをAPIではなくローカルで実行する必要がある場合を除いて、現在の商用ユースケースでは一般的にGPT-4oやGeminiよりも優れているわけではありません。[11]
MetaはLlamaの一次提供のホスト型推論サービスを提供していないことに注意してください。多くのプロバイダーがLlama推論エンドポイントを提供しており、サーバーレスGPUプラットフォームは独自のLlamaをデプロイするための様々なオプションを提供しています。
2025年にはオープンソース/オープンウェイトモデルで多くの進展が見られると予想しています。Llama 4は全く新しく、コミュニティはまだマルチターンの会話AIユースケースにおける実用的なパフォーマンスを評価している段階です。さらに、Alibaba(Qwen)、DeepSeek、Google(Gemma)、Microsoft(Phi)からの将来のオープンウェイトモデルが音声AIユースケースに適したオプションになる可能性が高いでしょう。
[11] ユースケースに合わせてLLMをファインチューニングする予定がある場合、Llama 3.3 70Bは非常に良い出発点です。ファインチューニングについては後述します。
4.2.4. 音声対音声モデルについて
音声対音声モデルは、比較的新しい、エキサイティングな開発です。音声対音声LLMは、テキストではなく音声で入力を受け取り、直接音声出力を生成することができます。これにより、音声エージェントのオーケストレーションループから音声認識とテキスト音声合成の部分が不要になります。
音声対音声モデルの潜在的な利点は以下の通りです:
- より低いレイテンシー
- 人間の会話のニュアンスをより良く理解する能力
- より自然な音声出力
OpenAIとGoogleの両社が音声対音声APIをリリースしています。大規模モデルのトレーニングを行い、音声AIアプリケーションを構築しているすべての人が、音声対音声モデルが音声AIの未来であると信じています。
しかし、現在の音声対音声モデルとAPIは、ほとんどの本番環境の音声AIユースケースにはまだ十分な性能を持っていません。
今日の最高の音声対音声モデルは、今日の最高のテキスト音声合成モデルよりも確かにより自然に聞こえます。OpenAIのgpt4o-audio-preview[12]モデルは、本当に音声AI未来のプレビューのように聞こえます。
[12] OpenAI音声APIドキュメント
しかし、音声対音声モデルは、テキストモードのLLMほど成熟しておらず、信頼性も高くありません。
- 理論的にはレイテンシーを低くすることが可能ですが、音声はテキストよりも多くのトークンを使用します。より大きなトークンコンテキストはLLMの処理が遅くなります。実際には、今日、音声モデルは通常、長いマルチターン会話ではテキストモデルよりも遅くなります。[13]
- より良い理解は、これらのモデルの実際の利点であるように見えます。これは特にGemini 2.0 Flash音声入力で顕著です。gpt4o-audio-previewについては、テキストモードのGPT-4oよりも小さく、やや能力の低いモデルであるため、状況はやや不明確です。
- より良い自然な音声出力は、今日では明らかに認識できます。しかし、音声LLMは音声モードで、テキストモードではあまり発生しない奇妙な出力パターンを持っています:単語の繰り返し、時々不気味の谷に落ちる談話マーカー、そして時々文を完成させない現象などです。
[13] 音声モデルのこのレイテンシーの問題は、キャッシング、巧妙なAPI設計、およびモデル自体のアーキテクチャの進化の組み合わせによって明らかに解決可能です。
これらの問題の中で最大のものは、マルチターン音声に必要な大きなコンテキストサイズです。この問題を解決し、ネイティブ音声のメリットをコンテキストサイズのデメリットなしに得る一つのアプローチは、各会話ターンをテキストと音声の混合として処理することです。最新のユーザーメッセージには音声を使用し、残りの会話履歴にはテキストを使用します。
OpenAIのベータ版音声対音声サービス — OpenAI Realtime API — は高速で、音声品質は驚くべきものです。しかし、このAPIの背後にあるモデルは、完全なGPT-4oではなく、より小さなgpt-4o-audio-previewです。そのため、命令の遵守とファンクションコーリングは同等ではありません。また、Realtime APIを使用して会話のコンテキストを管理するのは難しく、APIには新製品特有の荒さがいくつかあります。[14]
Google Multimodal Live APIは、もう一つの有望な — そしてその進化の初期段階にある — 音声対音声サービスです。このAPIは、Geminiモデルの近い将来の姿を示しています:長いコンテキストウィンドウ、優れたビジョン機能、高速な推論、優れた音声理解、コード実行、検索による基盤付け。OpenAI Realtime APIと同様に、Multimodal Live APIはまだほとんどの本番環境の音声AIアプリケーションに適した選択肢ではありません。
2025年には音声対音声の分野で多くの進展が見られると予想しています。しかし、本番環境の音声AIアプリケーションが今年中に音声対音声APIを使用し始めるかどうかは、まだ未解決の問題です。
[14] Realtime APIに関する詳細な注記を参照してください。
4.3. 音声認識
音声認識は音声AIの「入力」段階です。音声認識は一般的に文字起こしやASR(自動音声認識)とも呼ばれています。
音声AIのユースケースでは、非常に低いレイテンシーと非常に低い単語エラー率が必要です。残念ながら、低レイテンシーのために音声モデルを最適化すると、精度に悪影響を及ぼします。
今日、低レイテンシー向けに設計されていない非常に優れた文字起こしモデルがいくつかあります。Whisperは多くの製品やサービスで使用されているオープンソースモデルです。非常に優れていますが、通常は最初のトークンまでの時間が500ms以上かかるため、会話型音声AIのユースケースではほとんど使用されません。
4.3.1 Deepgram
現在、本番環境の音声AIエージェントのほとんどは、音声認識にDeepgramを使用しています。Deepgramは、低レイテンシー、低単語エラー率、低コストの非常に良い組み合わせを提供してきた長い実績を持つ商用音声認識AI研究所およびAPIプラットフォームです。
Deepgramのモデルは、セルフサービスAPIまたは顧客が自身のシステムで実行できるDockerコンテナとして利用可能です。
ほとんどの人はAPIを介してDeepgramの音声認識を使い始めます。米国のユーザーの場合、最初のトークンまでの時間は通常150msです。
スケーラブルなGPUクラスターの管理は重要な継続的なデブオプス作業であるため、DeepgramのAPIから自社インフラストラクチャ上でモデルをホスティングに移行することは、正当な理由がなければ行うべきではありません。正当な理由には以下が含まれます:
- 音声/文字起こしデータのプライバシー保持。DeepgramはBAAやデータ処理契約を提供していますが、一部の顧客は音声および文字起こしデータの完全な管理を望むでしょう。米国外の顧客は、自国または地域内にデータを保持する法的義務がある場合があります。(デフォルトでは、Deepgramの利用規約により、APIを通じて送信するすべてのデータでトレーニングすることが許可されています。エンタープライズプランではこれをオプトアウトできます。)
- レイテンシーの削減。Deepgramは米国外に推論サーバーを持っていません。ヨーロッパからのDeepgramのTTFTは約250ms、インドからは約350msです。
Deepgramはファインチューニングサービスを提供しており、比較的珍しい語彙、話し方、またはアクセントを含むユースケースがある場合、単語エラー率を下げるのに役立ちます。
4.3.2 プロンプトがLLMを助けることができる
Deepgramの文字起こしエラーの大部分は、リアルタイムストリームで文字起こしモデルが利用できるコンテキストが非常に少ないことに起因しています。
今日のLLMは文字起こしエラーを回避するのに十分賢いです。LLMが推論を実行する際、会話の全コンテキストにアクセスできます。そのため、入力がユーザーの発話の文字起こしであることをLLMに伝え、それに応じて推論するよう指示できます。
あなたは役立つ、簡潔で、信頼性の高い音声アシスタントです。あなたの主な目標は、音声認識の文字起こしにエラーが含まれていても、ユーザーの話された要求を理解することです。あなたの応答は音声合成システムを使用して音声に変換されます。したがって、あなたの出力はプレーンな、フォーマットされていないテキストでなければなりません。
ユーザーの文字起こしされた要求を受け取ったとき:
1. 可能性の高い文字起こしエラーを黙って修正してください。文字通りのテキストではなく、意図された意味に焦点を当ててください。ある単語が与えられたコンテキストで別の単語のように聞こえる場合は、推測して修正してください。例えば、文字起こしが「明日ミルク買う二」と言っている場合、これを「明日ミルク買う」と解釈してください。
2. ユーザーが明示的により詳細な回答を求めない限り、短く直接的な回答を提供してください。例えば、ユーザーが「今何時?」と言った場合、「午前2時38分です」と応答すべきです。ユーザーが「ジョークを教えて」と頼んだ場合、短いジョークを提供すべきです。
3. 常に明確さと正確さを優先してください。フォーマット、箇条書き、または余分な会話的な埋め草なしで、プレーンテキストで応答してください。
4. 時間に依存する質問をされた場合は、現在の日付(2025年2月3日)を使用して、最新の情報を提供してください。
5. ユーザーの要求を理解できない場合は、「申し訳ありませんが、理解できませんでした」と応答してください。
あなたの出力は直接音声に変換されるため、あなたの応答は自然に聞こえ、話し言葉の会話に適したものであるべきです。
音声AIエージェントのプロンプト例。
4.3.3 その他の音声認識オプション
2025年には音声認識の分野で多くの新しい開発が見られると予想しています。2025年4月初旬の時点で追跡している新しい開発のいくつかは:
- OpenAIは先日リリースした2つの新しい音声認識モデル、gpt-4o-transcribeとgpt-4o-mini-transcribeを発表しました。
- 音声モデルとインフラストラクチャ企業のGladiaはフランス語の音声AIで広く使用されており、現在ではフランス以外でもシェアを拡大しています。
- 他の評価の高い音声技術企業であるSpeechmaticsとAssemblyAIは、会話型音声のユースケースにより焦点を当て始め、ストリーミングAPIとより高速なTTFTを持つモデルを提供しています。
- NVIDIAはオープンソースの音声モデルを提供しており、ベンチマークで非常に優れたパフォーマンスを示しています。
- 推論企業GroqがホスティングするWhisper Large v3 Turboのバージョンは、現在中央値TTFTが300ms未満であり、会話型音声アプリケーションのオプションとなる範囲に入っています。これは、このレイテンシーを達成した最初のWhisper APIサービスです。
すべての大手クラウドサービスには音声認識APIがあります。現在、低レイテンシーの汎用英語文字起こしについては、どれもDeepgramほど優れていません。
しかし、以下の場合はAzure AI Speech、Amazon Transcribe、またはGoogle Speech-to-Textの使用を検討するかもしれません:
- これらのクラウドプロバイダーのいずれかに大規模なコミット済み支出またはデータ処理の取り決めがすでにある場合。
- ユーザーが英語を話さない場合。Deepgramは多くの非英語言語をサポートしていますが、異なる研究所はそれぞれ異なる言語の強みを持っています。非英語言語で運用する場合は、独自のテストを行う価値があります。
- 使用できるスタートアップクレジットがたくさんある場合!
4.3.4 Google Geminiでの文字起こし
低コストのネイティブ音声モデルとしてのGemini 2.0 Flashの強みを活用する一つの方法は、会話生成と文字起こしの両方にGemini 2.0を使用することです。
これを行うには、2つの並列推論プロセスを実行する必要があります。
- 一つの推論プロセスは会話応答を生成します。
- もう一つの推論プロセスはユーザーの発話を文字起こしします。
- 各音声入力は1ターンだけ使用されます。完全な会話コンテキストは常に、最新のユーザー発話の音声と、すべての以前の入力と出力のテキスト文字起こしで構成されます。
- これにより、現在のユーザー発話のネイティブ音声理解と、全体のコンテキストのトークン数削減という両方の利点が得られます。[15]
[15] 音声をテキストに置き換えることでトークン数が約10分の1に削減されます。10分間の会話では、処理される総トークン数(したがって入力トークンのコスト)が約100分の1に削減されます(会話履歴が毎ターン蓄積されるため)。
以下は、これらの並列推論プロセスをPipecatパイプラインとして実装するコードです。
pipeline = Pipeline(
[
transport.input(),
audio_collector,
context_aggregator.user(),
ParallelPipeline(
[ # transcribe
input_transcription_context_filter,
input_transcription_llm,
transcription_frames_emitter,
],
[ # conversation inference
conversation_llm,
],
),
tts,
transport.output(),
context_aggregator.assistant(),
context_text_audio_fixup,
]
)
ロジックは以下の通りです。
- 会話LLMはテキスト形式の会話履歴と、各新しいターンのユーザー発話をネイティブ音声として受け取り、会話応答を出力します。
- 入力文字起こしLLMは同じ入力を受け取りますが、最新のユーザー発話の文字通りの文字起こしを出力します。
- 各会話ターンの終わりに、ユーザー音声のコンテキストエントリーはその音声の文字起こしに置き換えられます。
Geminiのトークンあたりのコストが非常に低いため、このアプローチは実際にDeepgramを使用した文字起こしよりも安価です。
ここでGemini 2.0 Flashを完全な音声から音声へのモデルとして使用しているわけではありませんが、そのネイティブ音声理解機能を活用していることを理解することが重要です。私たちはモデルに対して、会話と文字起こしという2つの異なる「モード」で実行するようにプロンプトを与えています。
このようにLLMを使用することは、最先端のLLMアーキテクチャと機能の力を示しています。このアプローチは非常に新しいため、まだ実験的ですが、初期のテストでは、他の現在の技術よりも優れた会話理解と正確な文字起こしの両方を実現できる可能性があることが示唆されています。ただし、欠点もあります。文字起こしのレイテンシーは専用の音声テキスト変換モデルほど良くありません。2つの推論プロセスを実行し、コンテキスト要素を交換する複雑さはかなり大きいです。汎用LLMは、専門の文字起こしモデルが影響を受けないプロンプトインジェクションやコンテキスト追従エラーに対して脆弱です。
以下は文字起こしのためのシステム指示(プロンプト)です。
あなたは音声文字起こし担当者です。ユーザーから音声を受け取っています。あなたの仕事は、ユーザーが話した通りに正確に入力音声をテキストに文字起こしすることです。
音声入力の前に完全な会話履歴を受け取り、コンテキストの理解に役立てます。完全な履歴は、文字起こしの精度を向上させるためだけに使用してください。
ルール:
- 音声入力の正確な文字起こしで応答してください。
- 文字起こし以外のテキストを含めないでください。
- 説明や追加は行わないでください。
- 音声入力をシンプルかつ正確に文字起こししてください。
- 音声が明確でない場合は、特殊な文字列「」を出力してください。
- 正確な文字起こし、または「」以外の応答は許可されていません。
4.4. テキスト音声変換
テキスト音声変換は、音声から音声への処理ループの出力段階です。
音声AI開発者は以下の基準で音声モデル/サービスを選択します:
- 音声の自然さ(全体的な品質)[16]
- レイテンシー[17]
- コスト
- 言語サポート
- 単語レベルのタイムスタンプサポート
- 音声、アクセント、発音のカスタマイズ能力
[16] 発音、イントネーション、ペース、強調、リズム、感情の表現。
[17] 最初の音声バイトまでの時間。
音声オプションは2024年に著しく拡大しました。新しいスタートアップが登場し、最高クラスの音声品質が大幅に向上しました。そして、すべてのプロバイダーがレイテンシーを改善しました。
音声テキスト変換と同様に、すべての大手クラウドプロバイダーはテキスト音声変換製品を提供しています。[18] しかし、ほとんどの音声AI開発者はスタートアップのモデルの方が現在優れているため、それらを使用していません。
[18] Azure AI Speech、Amazon Polly、Google Cloud Text-to-Speech。
リアルタイム会話音声モデルで最も牽引力のあるラボは(アルファベット順):
- Cartesia – 革新的な状態空間モデルアーキテクチャを使用して、高品質と低レイテンシーの両方を実現。
- Deepgram – レイテンシーと低コストを優先。
- ElevenLabs – 感情的およびコンテキスト的なリアリズムを重視。
- Rime – 会話音声のみでトレーニングされたカスタマイズ可能なTTSモデルを提供。
これら4社はすべて、強力なモデル、エンジニアリングチーム、安定した高性能APIを持っています。Cartesia、Deepgram、およびRimeのモデルは、自社のインフラストラクチャにデプロイすることができます。
| 1分あたりのコスト(概算) | 中央値TTFB(ミリ秒) | P95 TTFB(ミリ秒) | |
|---|---|---|---|
| Cartesia | $0.02 | 170 | 240 |
| Deepgram | $0.008 | 90 | 1,840 |
| ElevenLabs Multilingual v2 | $0.03 | 700 | 1,100 |
| Rime | $0.024 | 310 | 370 |
1分あたりの概算コストと最初のバイトまでの時間の指標 – 2025年2月。コストはコミットされたボリュームと使用される機能によって異なることに注意してください。
音声テキスト変換と同様に、非英語音声モデルの品質とサポートには大きな差があります。非英語のユースケース向けに音声AIを構築している場合は、より広範なテストが必要になる可能性があります — より多くのサービスと音声をテストして、満足のいくソリューションを見つけてください。
すべての音声モデルは時々単語を誤って発音し、固有名詞や珍しい単語の発音方法を必ずしも知っているわけではありません。
一部のサービスでは発音を調整する機能を提供しています。これは、テキスト出力に特定の固有名詞が含まれることが事前にわかっている場合に役立ちます。音声サービスが音声的な調整をサポートしていない場合は、LLMに特定の単語の「発音に近い」スペルを出力するようにプロンプトを与えることができます。例えば、NVIDIAの代わりにin-vidiaなど。
あなたの応答で「NVIDIA」を「イン ヴィディア」に置き換え、
「GPU」を「ジー ピー ユー」に置き換えてください。
LLMテキスト出力を通じて発音を調整するプロンプト言語の例
会話音声のユースケースでは、ユーザーが聞いたテキストを追跡できることが、正確な会話コンテキストを維持するために重要です。これには、モデルが音声に加えて単語レベルのタイムスタンプメタデータを生成し、タイムスタンプデータが元の入力テキストに逆再構築できることが必要です。これは音声モデルにとって比較的新しい機能です。上記のすべてのサービスは単語レベルのタイムスタンプをサポートしています。
{
"type": "timestamps",
"context_id": "test-01",
"status_code": 206,
"done": false,
"word_timestamps": {
"words": ["What's", "the", "capital", "of", "France?"],
"start": [0.02, 0.3, 0.48, 0.6, 0.8],
"end": [0.3, 0.36, 0.6, 0.8, 1]
}
}
Cartesia APIからの単語レベルのタイムスタンプ。
さらに、本当に堅牢なリアルタイムストリーミングAPIが役立ちます。会話音声アプリケーションでは、多くの場合、複数の音声推論が並行してトリガーされます。音声エージェントコードは、進行中の推論を中断し、各推論リクエストを出力ストリームに関連付けることができる必要があります。音声モデルプロバイダーからのストリーミングAPIはすべて比較的新しく、まだ進化中です。現在、CartesiaとRimeがPipecatで最も成熟したストリーミングサポートを提供しています。
2025年も音声モデルの進歩が続くと予想されます。
- 上記の企業の数社は、年の前半に新しいモデルが登場することを示唆しています。
- OpenAIは最近新しいテキスト音声変換モデル、gpt-4o-mini-ttsをリリースしました。このモデルは完全に調整可能で、音声モデルに何を言うかだけでなく、どのように話すかも指示できる新しい可能性を開きます。openai.fmでgpt-4o-mini-ttsの調整を試すことができます。
- GroqとPlayAIは最近パートナーシップを発表しました。Groqは高速推論で知られており、PlayAIは30以上の言語をサポートする低レイテンシーの音声モデルを提供しています。
4.5. 音声処理
優れた音声AIプラットフォームやライブラリは、音声キャプチャと処理の複雑さをほとんど隠してくれます。しかし、複雑な音声エージェントを構築すると、いずれ音声処理のバグやコーナーケースに遭遇するでしょう。[19] そのため、音声入力パイプラインを簡単に見ておく価値があります。
[19] … これはソフトウェアのすべてのことに、そしておそらく人生のほとんどのことに当てはまります。
4.5.1 マイクと自動ゲイン制御
現在のマイクは、大量の低レベルソフトウェアと結合した非常に洗練されたハードウェアデバイスです。これは通常素晴らしいことです — モバイルデバイス、ラップトップ、Bluetoothイヤホンに内蔵された小さなマイクから素晴らしい音声を得ることができます。
しかし、時にこの低レベルソフトウェアは私たちが望むことをしません。特に、Bluetoothデバイスは音声入力に数百ミリ秒のレイテンシーを追加することがあります。これは音声AI開発者としてあなたのコントロール外のことですが、特定のユーザーが使用しているオペレーティングシステムと入力デバイスによってレイテンシーが大きく異なる可能性があることを認識しておく価値があります。

ほとんどの音声キャプチャパイプラインは、入力信号に対してある程度の自動ゲイン制御を適用します。これも通常は望ましいことです。なぜなら、ユーザーとマイクの距離などを補正するからです。一部の自動ゲイン制御を無効にすることはできますが、一般消費者向けデバイスでは通常、完全に無効にすることはできません。
4.5.2 エコーキャンセレーション
ユーザーが電話を耳に当てている場合や、ヘッドフォンを着用している場合は、ローカルマイクとスピーカー間のフィードバックについて心配する必要はありません。しかし、ユーザーがスピーカーフォンで話している場合や、ヘッドフォンなしでラップトップを使用している場合は、優れたエコーキャンセレーションが非常に重要です。
エコーキャンセレーションはレイテンシーに非常に敏感であるため、エコーキャンセレーションはクラウドではなくデバイス上で実行する必要があります。現在、優れたエコーキャンセレーションは電話スタック、ウェブブラウザ、WebRTCネイティブモバイルSDKに組み込まれています。[20]
したがって、音声AI、WebRTC、または電話SDKを使用している場合は、ほとんどの実際のシナリオで「正常に動作する」と信頼できるエコーキャンセレーションがあるはずです。独自の音声AIキャプチャパイプラインを構築している場合は、エコーキャンセレーションロジックを統合する方法を考える必要があります。例えば、WebSocketベースのReact Nativeアプリケーションを構築している場合、デフォルトではエコーキャンセレーションはありません。[21]
[20] Firefoxのエコーキャンセレーションはあまり良くないことに注意してください。音声AI開発者はChromeとSafariを主要プラットフォームとして構築し、時間が許す限り、Firefoxは二次的なプラットフォームとしてのみテストすることをお勧めします。
[21] 最近、React Nativeアプリの音声問題のデバッグを手伝いました。根本的な原因は、音声AIやWebRTC SDKを使用していなかったため、エコーキャンセレーションを実装する必要があることに気づいていなかったことでした。
4.5.3 ノイズ抑制、音声、音楽
電話やWebRTCの音声キャプチャパイプラインは、ほとんどの場合「音声モード」がデフォルトです。音声は音楽よりもはるかに圧縮でき、ノイズ削減やエコーキャンセレーションアルゴリズムは、より狭い帯域の信号に対して実装が容易です。
多くの電話プラットフォームは8kHzの音声のみをサポートしています。これは現代の基準では明らかに低品質です。このような制限のあるシステムを経由している場合、それについてできることは何もありません。ユーザーはその品質に気づくかもしれませんし、気づかないかもしれません — ほとんどの人は電話の音声品質に対する期待が低いです。
WebRTCは非常に高品質の音声をサポートしています。[22] WebRTCのデフォルト設定は通常、48kHzのサンプルレート、シングルチャンネル、32kbpsのOpusエンコーディング、および適度なノイズ抑制アルゴリズムです。これらの設定は音声に最適化されています。幅広いデバイスと環境で機能し、一般的に音声AIに適した選択です。
これらの設定では音楽は良く聞こえません!
WebRTC接続を介して音楽を送信する必要がある場合は、次のようにします:
- エコーキャンセレーションをオフにする(ユーザーはヘッドフォンを着用する必要があります)。
- ノイズ抑制をオフにする。
- オプションで、ステレオを有効にする。
- Opusエンコーディングのビットレートを上げる(モノラルの場合は64kbps、ステレオの場合は96kbpsまたは128kbpsが適切です)。
[22] 高品質音声のいくつかのユースケース:
- LLM教師による音楽レッスン。
- バックグラウンドサウンドや音楽を含むポッドキャストの録音。
- AI音楽をインタラクティブに生成する。
4.5.4 エンコーディング
エンコーディングは、ネットワーク接続を介して送信するために音声データがフォーマットされる方法の一般的な用語です。[23]
[23] (またはファイルに保存するため。)
リアルタイム通信で一般的に使用されるエンコーディングには以下があります:
- 16ビットPCM形式の非圧縮オーディオ。
- Opus — WebRTCおよび一部の電話システム。
- G.711 — 広くサポートされている標準的な電話コーデック。
| コーデック | ビットレート | 品質 | ユースケース |
|---|---|---|---|
| 16ビットPCM | 384 kbps(モノラル24 kHz) | 非常に高い(ほぼロスレス) | 音声録音、組み込みシステム、シンプルなデコードが重要な環境 |
| Opus 32 kbps | 32 kbps | 良好(音声に最適化された心理音響圧縮) | ビデオ通話、低帯域幅ストリーミング、ポッドキャスト |
| Opus 96 kbps | 96 kbps | 非常に良好〜優秀(心理音響圧縮) | ストリーミング、音楽、音声アーカイブ |
| G.711(8 kHz) | 64 kbps | 低品質(限られた帯域幅、音声中心) | レガシーVoIPシステム、電話、FAX送信、ボイスメッセージング |
音声AIで最もよく使用されるオーディオコーデック
Opusはこれら3つのオプションの中で断然最良です。Opusはウェブブラウザに組み込まれており、低遅延コーデックとして一から設計され、非常に効率的です。また、幅広いビットレートで優れたパフォーマンスを発揮し、音声と高忠実度の両方のユースケースをサポートしています。
16ビットPCMは「生の音声」です。PCMオーディオフレームをソフトウェアサウンドチャネルに直接送信できます(サンプルレートとデータタイプが正しく指定されていると仮定して)。ただし、この非圧縮オーディオはインターネット接続を介して送信したいものではありません。24kHzのPCMのビットレートは384kbpsです。これは多くの実際のエンドユーザーデバイスからの接続がリアルタイムでバイトを配信するのに苦労するほど大きなビットレートです。
4.5.5 サーバーサイドのノイズ処理とスピーカー分離
音声認識と音声アクティビティ検出モデルは通常、一般的な環境ノイズ(街の音、犬の鳴き声、マイクの近くの大きなファン音、キーボードのクリック音など)を無視できます。そのため、多くの人間対人間のユースケースで重要な従来の「ノイズ抑制」アルゴリズムは、音声AIにとってはそれほど重要ではありません。
しかし、音声AIにとって特に価値のある音声処理の一種があります:主要話者分離です。主要話者分離は背景の会話を抑制します。これにより文字起こしの精度が大幅に向上します。
空港のような環境から音声エージェントに話しかけようとしている状況を考えてみてください。あなたのスマートフォンのマイクは、ゲートアナウンスや通りすがりの人々からの多くの背景会話を拾う可能性があります。LLMが見るテキスト文字起こしにそのような背景会話を含めたくないでしょう!
あるいは、リビングルームでテレビやラジオがバックグラウンドで流れている状態のユーザーを想像してみてください。人間は一般的に低音量の背景会話をフィルタリングするのが得意なため、カスタマーサポートに電話する前にテレビやラジオの電源を切ることを必ずしも考えないでしょう。
あなた自身の音声AIパイプラインで使用できる最高の話者分離モデルは、Krispが販売しています。ライセンスは企業ユーザー向けであり、安価ではありません。しかし、大規模な商用ユースケースでは、音声エージェントのパフォーマンス向上によってそのコストは正当化されます。
OpenAIは最近、Realtime APIの一部として新しいノイズ削減機能をリリースしました。リファレンスドキュメントはこちらです。
pipeline = Pipeline(
[
transport.input(),
krisp_filter,
vad_turn_detector,
stt,
context_aggregator.user(),
llm,
tts,
transport.output(),
context_aggregator.assistant(),
]
)
Krispの処理要素を含むPipecatパイプライン
4.5.6 音声アクティビティ検出
音声アクティビティ検出(VAD)ステージはほぼすべての音声AIパイプラインの一部です。VADは音声セグメントを「音声」と「非音声」に分類します。VADについては、以下のターン検出セクションで詳しく説明します。
4.6. ネットワークトランスポート
4.6.1 WebSocketsとWebRTC
WebSocketsとWebRTCはどちらもAIサービスのオーディオストリーミングに使用されています。
WebSocketsはサーバー間のユースケースに最適です。また、レイテンシーが主な懸念事項ではないユースケースにも適しており、プロトタイピングや一般的な開発に適しています。
WebSocketsは、クライアント-サーバー間のリアルタイムメディア接続の本番環境では使用すべきではありません。
ブラウザやネイティブモバイルアプリを構築していて、会話のレイテンシーがアプリケーションにとって重要な場合は、WebRTC接続を使用してアプリから音声を送受信する必要があります。
エンドユーザーデバイスとの間のリアルタイムメディア配信にWebSocketsを使用する主な問題点は次のとおりです:
- WebSocketsはTCPに基づいているため、音声ストリームはヘッドオブラインブロッキングの影響を受けます。
- WebRTCで使用されるOpusオーディオコーデックは、WebRTCの帯域幅推定とパケットペーシング(輻輳制御)ロジックと密接に結合されており、WebSocket接続ではレイテンシーが蓄積する可能性がある様々な実世界のネットワーク動作に対してWebRTCオーディオストリームを耐性のあるものにしています。
- Opusオーディオコーデックは非常に優れた前方誤り訂正機能を持ち、比較的高いパケット損失に対して耐性があります。(ただし、これはネットワークトランスポートが遅延到着パケットをドロップでき、ヘッドオブラインブロッキングを行わない場合にのみ役立ちます。)
- WebRTCオーディオは自動的にタイムスタンプが付けられるため、再生と割り込みロジックが簡単になります。
- WebRTCには詳細なパフォーマンスとメディア品質の統計情報のためのフックが含まれています。優れたWebRTCプラットフォームは詳細なダッシュボードと分析を提供します。このレベルの可観測性はWebSocketsでは非常に難しいか不可能です。
- WebSocketの再接続ロジックを堅牢に実装するのは非常に難しいです。ping/ackフレームワークを構築する必要があります(またはWebSocketライブラリが提供するフレームワークを完全にテストして理解する必要があります)。TCPタイムアウトと接続イベントはプラットフォームによって動作が異なります。
- 最後に、現在の優れたWebRTC実装には、非常に優れたエコーキャンセレーション、ノイズ削減、自動ゲイン制御が付属しています。

4.6.2 HTTP
HTTPも音声AIにとって依然として有用で重要です!HTTPはインターネット上のサービス相互接続のためのリンガフランカ(共通言語)です。REST APIはHTTPです。WebhookもHTTPです。
テキスト指向の推論は通常HTTPを介して行われるため、音声AIパイプラインは会話ループのLLM部分のためにHTTP APIを呼び出すことがよくあります。
音声エージェントは、外部サービスや内部APIと統合する際にもHTTPを使用します。有用な手法の一つは、LLM関数呼び出しをHTTPエンドポイントにプロキシすることです。これにより、音声AIエージェントコードとDevOpsを関数実装から切り離すことができます。
マルチモーダルAIアプリケーションでは、HTTPとWebRTCの両方のコードパスを実装することがよくあります。テキストモードと音声モードの両方をサポートするチャットアプリを想像してみてください。会話状態はどちらの接続パスからもアクセス可能である必要があり、これはクライアントとサーバー側のコード(例えば、KubernetesポッドやDockerコンテナがどのようにアーキテクチャされるか)に影響を与えます。
HTTPの2つの欠点は、レイテンシーと長時間の双方向接続の実装の難しさです。
- 暗号化されたHTTP接続のセットアップには複数のネットワークラウンドトリップが必要です。メディア接続のセットアップ時間を30ms未満にすることは合理的に難しく、最初のバイト送信までの現実的な時間は、高度に最適化されたサーバーでも100msに近いです。
- 長時間の双方向HTTP接続の管理は十分に難しいため、通常はWebSocketsを使用する方が良いでしょう。
- HTTPはTCPベースのプロトコルであるため、WebSocketsに影響するのと同じヘッドオブラインブロッキングの問題がHTTPにも影響します。
- HTTPを介して生のバイナリデータを送信することは一般的ではないため、ほとんどのAPIはバイナリデータをbase64エンコードすることを選択しており、これによりメディアストリームのビットレートが増加します。
これでQUICについて説明します…

ネットワーク通信にHTTPとWebRTCの両方を使用する音声AIエージェント。
4.6.3 QUICとMoQ
QUICは、HTTPの最新バージョン(HTTP/3)のトランスポート層として設計された新しいネットワークプロトコルであり、他のインターネット規模のユースケースも柔軟にサポートします。
QUICはUDPベースのプロトコルであり、HTTPに関する上記の問題すべてに対処します。QUICを使用すると、より高速な接続時間、双方向ストリーム、ヘッドオブラインブロッキングなしが実現します。GoogleとFacebookは着実にQUICを展開しているため、現在では一部のHTTPリクエストはTCPではなくUDPパケットとしてインターネットを通過しています。[24]
[24] 長い間インターネット上で何かを構築してきた人にとっては、これは少し🤯です。HTTPは常にTCPベースのプロトコルでした!
QUICはインターネット上のメディアストリーミングの将来の大きな部分を担うでしょう。ただし、リアルタイムメディアストリーミング用のQUICベースのプロトコルへの移行には時間がかかります。QUICベースの音声エージェントを構築する際の障害の一つは、SafariがWebSocketsのQUICベースの進化版であるWebTransportをまだサポートしていないことです。
Media over QUIC IETF作業グループ[25]は、「メディアの取り込みと配信のためのシンプルな低レイテンシーメディア配信ソリューション」の開発を目指しています。すべての標準と同様に、最もシンプルな構成要素で可能な限り広範囲の重要なユースケースをサポートする方法を詰めるのは簡単ではありません。人々はQUICをオンデマンドビデオストリーミング、大規模ビデオブロードキャスト、ライブビデオストリーミング、多数の参加者を持つ低レイテンシーセッション、および低レイテンシーの1対1セッションに使用することに期待しています。
リアルタイム音声AIのユースケースは、MoQ標準の開発に影響を与えるちょうど良いタイミングで成長しています。
4.6.4 ネットワークルーティング
長距離ネットワーク接続は、基盤となるネットワークプロトコルが何であれ、レイテンシーとリアルタイムメディアの信頼性に問題があります。
リアルタイムメディア配信では、サーバーをユーザーにできるだけ近い場所に配置することが望ましいです。
例えば、イギリスのユーザーから北カリフォルニアのAWS us-west-1でホストされているサーバーへのパケットの往復時間は通常約140ミリ秒です。比較すると、同じユーザーからAWS eu-west-2への往復時間は一般的に15ミリ秒以下です。

イギリスのユーザーからAWS us-west-1へのRTTは、AWS eu-west-2への場合よりも約100ms長い
これは100ミリ秒以上の差です — 音声から音声へのレイテンシー目標が1,000ミリ秒の場合、レイテンシー「予算」の10パーセントに相当します。
エッジルーティング
すべてのユーザーの近くにサーバーを配置できない場合もあります。
世界中のユーザーに15msのRTTを実現するには、少なくとも40のグローバルデータセンターへの展開が必要です。これは大きなDevOpsの仕事です。また、GPUを必要とするワークロードを実行している場合や、それ自体がグローバルに展開されていないサービスに依存している場合は、不可能かもしれません。
光の速度を欺くことはできません。[26] しかし、ルートの変動や輻輳を避けるよう努力することはできます。
[26] 古代のネットワークエンジニアの知恵 – 編
鍵となるのは、パブリックインターネットルートをできるだけ短く保つことです。ユーザーを近くのエッジサーバーに接続します。そこからプライベートルートを使用します。
このエッジルーティングによりパケットRTTの中央値が減少します。プライベートバックボーン経由のイギリス→北カリフォルニアルートは約100ミリ秒になる可能性があります。100 ms(長距離プライベートルート)+ 15 ms(パブリックインターネット経由の最初のホップ)= 115 ms。このプライベートルートの中央値RTTは、パブリックルートの中央値RTTよりも25ms優れています。

イギリスからAWS us-west-1へのエッジルート。パブリックネットワーク経由の最初のホップのRTTは依然として15msです。しかし、プライベートネットワーク経由の北カリフォルニアへの長距離ルートのRTTは100msです。合計RTTの115msは、イギリスからus-west-1へのパブリックルートよりも25ms速いです。また、パケット損失とジッターが大幅に少ないため、安定性も大幅に向上しています。
中央値RTTの改善よりもさらに重要なのは、配信の信頼性向上とジッター[27]の低減です。プライベートルートのP95 RTTは、パブリックルートのP95よりも大幅に低くなります。[28]
これは、長距離パブリックルート経由のリアルタイムメディア接続が、プライベートルートを使用する接続よりも測定可能なほど遅延することを意味します。各オーディオパケットをできるだけ早く配信しようとしていますが、オーディオパケットを順番に再生する必要があることを思い出してください。1つのパケットが遅延すると、ジッターバッファを拡大せざるを得なくなり、遅延パケットが到着するまで他の受信パケットを保持することになります(または、時間がかかりすぎると判断して、高度な数学的処理やグリッチのある音声サンプルでギャップを埋めることになります)。
[27] ジッターとは、パケットがルートを通過するのにかかる時間の変動性です。
[28] P95は測定値の95パーセンタイルです。P50は中央値(50パーセンタイル)です。大まかに言えば、P50を平均的なケース、P95を「典型的な最悪のケース」接続の大まかな感覚を捉えるものと考えます。

ジッターバッファ — より大きなジッターバッファは、音声と映像の知覚される遅延の増加に直接つながります。ジッターバッファをできるだけ小さく保つことが、良好なユーザーエクスペリエンスに大きく貢献します。
優れたWebRTCインフラストラクチャプロバイダーはエッジルーティングを提供します。彼らはサーバークラスターの場所を示し、プライベートルートのパフォーマンスを示す指標を提供できるでしょう。
4.7. ターン検出
ターン検出とは、ユーザーが話し終えてLLMが応答することを期待しているタイミングを判断することです。
学術文献では、この問題のさまざまな側面はフレーズ検出、音声セグメンテーション、エンドポインティングと呼ばれています。(これについて学術文献があるという事実は、これが簡単な問題ではないことを示しています。)
私たち(人間)は他の誰かと話すたびにターン検出を行っています。そして、必ずしも正確にできるわけではありません![29]
したがって、ターン検出は難しい問題であり、完璧な解決策はありません。しかし、一般的に使用されているさまざまなアプローチについて説明しましょう。
[29] 特に音声通話では、視覚的な手がかりがないため。
4.7.1 音声活動検出
現在、音声AIエージェントのターン検出の標準的な方法は、長い間隔が発生したらユーザーが話し終えたと判断することです。
音声AIエージェントのパイプラインは、小型の特殊な音声活動検出(VAD)モデルを使用して間隔を識別します。VADモデルは、音声セグメントを「発話」または「非発話」として分類するよう訓練されています。(これは音量レベルのみに基づいて間隔を識別しようとするよりもはるかに堅牢です。)
VADは音声AI接続のクライアント側でもサーバー側でも実行できます。クライアントで大量の音声処理を行う必要がある場合は、おそらくクライアントでVADを実行してそれを容易にする必要があるでしょう。例えば、組み込みデバイスでウェイクワードを識別し、フレーズの最初にウェイクワードを検出した場合にのみ音声をネットワーク経由で送信する場合などです。「ねえ、Siri...」
しかし一般的には、VADを音声AIエージェント処理ループの一部として実行する方がシンプルです。また、ユーザーが電話で接続している場合は、VADを実行できるクライアントがないため、サーバー上で実行する必要があります。
音声AIで最も頻繁に使用されるVADモデルはSilero VADです。このオープンソースモデルはCPU上で効率的に実行され、複数の言語をサポートし、8kHzと16kHzの両方の音声に適しており、Webブラウザで使用するためのwasmパッケージとして利用可能です。リアルタイムのモノラル音声ストリームでSileroを実行すると、通常、一般的な仮想マシンのCPUコアの1/8未満のリソースしか使用しません。
ターン検出アルゴリズムにはいくつかの設定パラメータがあります:
- ターン終了と判断するために必要な間隔の長さ。
- 発話開始イベントをトリガーするために必要な発話セグメントの長さ。
- 各音声セグメントを発話として分類する信頼度レベル。
- 発話セグメントの最小音量。

音声活動検出処理ステップ。ここでは音声テキスト変換の直前に実行するよう設定されています
# Pipecatの4つの設定可能なVAD
# パラメータの名前とデフォルト値
VAD_STOP_SECS = 0.8
VAD_START_SECS = 0.2
VAD_CONFIDENCE = 0.7
VAD_MIN_VOLUME = 0.6
これらのパラメータを調整することで、特定のユースケースに対するターン検出の動作を大幅に改善できます。
4.7.2 プッシュトゥトーク
発話の間隔に基づいてターン検出を行う明らかな問題は、人々が話し終わっていないのに間隔を置くことがあるということです。
個人の話し方のスタイルは様々です。会話の種類によっては、人々はより多くの間隔を置くことがあります。
長い間隔を設定すると会話が不自然になり、非常に悪いユーザーエクスペリエンスとなります。しかし、短い間隔を設定すると、音声エージェントがユーザーを頻繁に中断することになり、これもまた悪いユーザーエクスペリエンスです。
間隔ベースのターン検出に代わる最も一般的な方法はプッシュトゥトークです。プッシュトゥトークとは、ユーザーが話し始めるときにボタンを押すか押し続け、話し終わったときにボタンをもう一度押すか離すことを要求することを意味します。(昔のトランシーバーの仕組みを考えてみてください。)
プッシュトゥトークではターン検出は明確です。しかし、ユーザーエクスペリエンスは単に話すのとは異なります。
電話を使用する音声AIエージェントではプッシュトゥトークは不可能です。
4.7.3 エンドポイントマーカー
特定の単語をターン終了マーカーとして使用することもできます。(CBラジオで話すトラック運転手が「どうぞ」と言うのを考えてみてください。)
特定のエンドポイントマーカーを識別する最も簡単な方法は、各文字起こしフラグメントに対して正規表現マッチングを実行することです。しかし、小型の言語モデルを使用してエンドポイントの単語やフレーズを検出することもできます。
明示的なエンドポイントマーカーを使用する音声AIアプリはかなり珍しいです。ユーザーはこれらのアプリとの対話方法を学ぶ必要があります。しかし、このアプローチは特殊なユースケースでは非常にうまく機能することがあります。
例えば、昨年、誰かがサイドプロジェクトとして自分のために構築した執筆アシスタントの素晴らしいデモを見ました。彼らはターンエンドポイントを示し、モード間を切り替えるためにさまざまなコマンドフレーズを使用していました。
4.7.4 コンテキスト認識ターン検出
人間がターン検出を行う際には、さまざまな手がかりを使用します:
- 「えーと」などのフィラー語が継続的な発話を示す可能性が高いという識別。
- 文法構造。
- 電話番号が特定の桁数を持つなどのパターンの知識。
- 間隔の前の最後の単語を引き延ばすなどのイントネーションと発音パターン。
ディープラーニングモデルはパターンの識別に非常に優れています。LLMは多くの潜在的な文法知識を持ち、フレーズのエンドポインティングを行うようプロンプトできます。より小型の特殊な分類モデルは、言語、イントネーション、発音パターンで訓練できます。
音声エージェントの商業的重要性がますます高まるにつれて、コンテキスト認識音声AIターン検出のための新しいモデルが登場すると予想されます。
主に2つのアプローチがあります:
- リアルタイムで実行できる小型のターン検出モデルを訓練します。このモデルをVADと組み合わせて使用します。短いVADタイムアウトを設定し、VADの後にインラインでターン検出モデルを実行し、ターン検出モデルがフレーズエンドポイントが識別されたという高い信頼度を持つ場合にのみ、ユーザーの発話をパイプラインに送信します。Pipecatコミュニティは、英語での特定のフレーズエンドポインティングタスクに対して優れたパフォーマンスを発揮する、小型のオープンソースのネイティブ音声モデルを開発しました。[30]
- 大規模なLLMとfew-shotプロンプトを使用してターン検出を実行します。大規模なLLMは通常、インラインでパイプラインをブロックするには遅すぎます。これを回避するために、パイプラインを分割し、ターン検出と「貪欲な」会話推論を並行して行うことができます。
[
transport.input(),
vad,
audio_accumulater,
ParallelPipeline(
[
FunctionFilter(filter=block_user_stopped_speaking),
],
[
ParallelPipeline(
[
classifier_llm,
completeness_check,
],
[
tx_llm,
user_aggregator_buffer,
],
)
],
[
conversation_audio_context_assembler,
conversation_llm,
bot_output_gate,
],
),
tts,
transport.output(),
context_aggregator.assistant(),
],
Gemini 2.0 Flashネイティブ音声入力を使用したコンテキスト認識ターン検出のためのPipecatパイプラインコード。ターン検出と貪欲な会話推論が並行して実行されます。ターン検出推論がフレーズエンドポイントを検出するまで出力はゲートされます。
OpenAIは最近、Realtime APIに新しいコンテキスト認識ターン検出機能をリリースしました。彼らはこの機能を、よりシンプルなサーバーVAD(間隔ベースのターン検出)と対比してセマンティックVADと呼んでいます。ドキュメントはこちらです。
4.8. 割り込み処理
割り込み処理とは、ユーザーが音声AIエージェントを中断できるようにすることです。割り込みは会話の通常の一部であるため、割り込みを適切に処理することが重要です。
割り込み処理を実装するには、パイプラインのすべての部分をキャンセル可能にする必要があります。また、クライアント上の音声再生を非常に迅速に停止できる必要があります。
一般的に、構築しているフレームワークは割り込みがトリガーされたときにすべての処理を停止する処理を行います。しかし、リアルタイムより速く生の音声フレームを送信するAPIを直接使用している場合は、再生を手動で停止し、オーディオバッファをフラッシュする必要があります。
4.8.1 不要な割り込みを避ける
意図しない割り込みのいくつかの原因に注意する価値があります。
- 音声として分類される一時的なノイズ。優れたVADモデルは音声と「ノイズ」を分離する優れた仕事をします。しかし、特定の種類の短く鋭い初期音声は、発話の始めに現れると中程度の音声信頼度が付与されます。咳やキーボードのクリック音はこのカテゴリに含まれます。VADの開始セグメント長と信頼度レベルを調整して、この種の割り込みを最小限に抑えることができます。トレードオフは、開始セグメント長を長くし、信頼度のしきい値を上げると、完全な発話として検出したい非常に短いフレーズに問題が生じることです。[31]
- エコーキャンセレーションの失敗。エコーキャンセレーションアルゴリズムは完璧ではありません。無音から音声再生への移行は特に難しいです。音声エージェントのテストを多く行った場合、ボットが話し始めるとすぐに自分自身を中断するのを聞いたことがあるでしょう。犯人はエコーキャンセレーションで、初期の音声の一部がマイクにフィードバックされてしまうことです。最小VAD開始セグメント長はこの問題を回避するのに役立ちます。また、急激な音量変化を避けるために音声音量レベルに指数平滑化[32]を適用することも有効です。
- バックグラウンドの会話。VADモデルはユーザーの音声とバックグラウンドの会話を区別しません。バックグラウンドの会話が音量しきい値より大きい場合、バックグラウンドの会話が割り込みをトリガーします。スピーカー分離音声処理ステップを追加することで、バックグラウンド会話による不要な割り込みを減らすことができます。上記のサーバーサイドのノイズ処理とスピーカー分離セクションの議論を参照してください。
4.8.2 割り込み後の正確なコンテキストの維持
LLMはリアルタイムより速く出力を生成するため、割り込みが発生した場合、ユーザーに送信するためにキューに入れられたLLM出力が多くあることがよくあります。
通常、会話コンテキストはユーザーが実際に聞いたもの(パイプラインがリアルタイムより速く生成したものではなく)と一致させたいと思うでしょう。
また、会話コンテキストをテキストとして保存している可能性もあります。[33]
そのため、ユーザーが実際に聞いたテキストを把握する方法が必要です!
最高の音声認識サービスは単語レベルのタイムスタンプデータを報告できます。これらの単語レベルのタイムスタンプを使用して、ユーザーが聞いた音声と一致するアシスタントメッセージテキストをバッファリングして組み立てます。上記のテキスト読み上げセクションの単語レベルのタイムスタンプに関する議論を参照してください。Pipecatはこれを自動的に処理します。
[31] Pipecatの標準パイプライン構成は、不要な割り込みと見逃された発話の両方を避けるためにVADと文字起こしイベントを組み合わせています。
[33] 標準的なコンテキスト構造は、OpenAIによって開発されたユーザー/アシスタントメッセージリスト形式です。
4.9. 会話コンテキストの管理
LLMはステートレスです。これは、複数ターンの会話では、新しい応答を生成するたびに、以前のすべてのユーザーとエージェントのメッセージ、およびその他の設定要素をLLMに再度フィードバックする必要があることを意味します。
ターン1:
ユーザー: フランスの首都は何ですか?
LLM: フランスの首都はパリです。
ターン2:
ユーザー: フランスの首都は何ですか?
LLM: フランスの首都はパリです。
ユーザー: エッフェル塔はそこにありますか?
LLM: はい、エッフェル塔はパリにあります。
ターン3:
ユーザー: フランスの首都は何ですか?
LLM: フランスの首都はパリです。
ユーザー: エッフェル塔はそこにありますか?
LLM: はい、エッフェル塔はパリにあります。
ユーザー: それはどれくらいの高さですか?
LLM: エッフェル塔は約330メートルの高さがあります。
毎ターン、LLMに会話履歴全体を送信する。
各推論操作(各会話ターン)で、LLMに以下を送信できます:
- システム指示
- 会話メッセージ
- LLMが使用するツール(関数)
- 設定パラメータ(例えば、temperature)
4.9.1 LLM API間の違い
この一般的な設計は、今日のすべての主要なLLMで同じです。
しかし、様々なプロバイダーのAPI間には違いがあります。OpenAI、Google、Anthropicはすべて異なるメッセージ形式、ツール/関数定義の構造の違い、システム指示の指定方法の違いがあります。
APIコールをOpenAIの形式に変換するサードパーティのAPIゲートウェイやソフトウェアライブラリがあります。これは価値があります。なぜなら、異なるLLM間を切り替えることができるのは有用だからです。しかし、これらのサービスは常に違いを適切に抽象化できるわけではありません。新機能や各APIに固有の機能は常にサポートされているわけではありません。(そして時には変換層にバグがあることもあります。)
AIエンジニアリングのこの比較的初期の段階では、抽象化するかしないかは依然として問題です。[34]
例えば、Pipecatは、コンテキストメッセージとツール定義の両方についてOpenAI形式との間でメッセージを変換します。しかし、これを行うかどうか、どのように行うかは、コミュニティでかなりの議論の対象でした![35]
[34] 自分へのメモ:Claudeに良いハムレットのジョークを考えてもらう – 編
[35] このようなトピックに興味がある場合は、Pipecat Discordに参加して、そこでの会話に参加することを検討してください。
4.9.2 ターン間でのコンテキストの修正
マルチターンコンテキストを管理する必要があることは、音声AIエージェントの開発の複雑さを増します。一方で、コンテキストを遡って修正することは有用な場合があります。各会話ターンで、LLMに送信する内容を正確に決定できます。
LLMは常に完全な会話コンテキストを必要とするわけではありません。コンテキストを短縮または要約することで、レイテンシーを減らし、コストを削減し、音声AIエージェントの信頼性を向上させることができます。このトピックについては、以下のスクリプティングと指示の遵守セクションで詳しく説明します。
4.10. 関数呼び出し
本番環境の音声AIエージェントは、LLM関数呼び出しに大きく依存しています。
関数呼び出しは以下のために使用されます:
- 検索拡張生成のための情報取得。
- 既存のバックエンドシステムやAPIとの対話。
- 電話技術スタックとの統合 — 通話転送、キューイング、DTMFトーンの送信。
- スクリプト遵守 – ワークフロー状態遷移を実装する関数呼び出し。
4.10.1 音声AIコンテキストにおける関数呼び出しの信頼性
音声AIエージェントがますます複雑なユースケースに展開されるにつれて、信頼性の高い関数呼び出しがますます重要になってきています。
最先端のLLMは関数呼び出しにおいて着実に改善されていますが、音声AIのユースケースはLLM関数呼び出し機能を限界まで拡張する傾向があります。
音声AIエージェントは以下の傾向があります:
- マルチターン会話で関数を使用する。マルチターン会話では、ユーザーとアシスタントのメッセージが毎ターン追加されるにつれて、プロンプトはますます複雑になります。このプロンプトの複雑さはLLM関数呼び出し機能を低下させます。
- 複数の関数を定義する。音声AIワークフローでは5つ以上の関数が必要なことが一般的です。
- セッション中に関数を何度も呼び出す。
私たちは主要なAIモデルのリリースをすべて徹底的にテストし、これらのモデルをトレーニングしている人々と頻繁に話しています。上記の属性はすべて、現世代のLLMのトレーニングに使用されたデータと比較して、ある程度分布外であることは明らかです。
これは、現世代のLLMが一般的な関数呼び出しベンチマークでうまく機能する場合でも、音声AIのユースケースで苦戦することを意味します。異なるLLMや同じモデルの異なる更新は、関数呼び出しのパフォーマンスが異なり、異なる状況下で異なる種類の関数呼び出しに対して異なる性能を示します。
音声AIエージェントを構築している場合、アプリの関数呼び出しパフォーマンスをテストするための独自の評価を開発することが重要です。以下の音声AI評価セクションを参照してください。
4.10.2 関数呼び出しのレイテンシー
関数呼び出しは4つの理由でレイテンシーを追加します(潜在的にかなりのレイテンシー):
- LLMが関数呼び出しが必要だと判断すると、関数呼び出しリクエストメッセージを出力します。その後、コードは特定の関数に対して必要な処理を行い、同じコンテキストに関数呼び出し結果メッセージを追加して再度推論を呼び出します。したがって、関数が呼び出されるたびに、1回ではなく2回の推論呼び出しを行う必要があります。
- 関数呼び出しリクエストはストリーミングできません。関数呼び出しを実行する前に、関数呼び出しリクエストメッセージ全体が必要です。
- プロンプトに関数定義を追加するとレイテンシーが増加する可能性があります。これは少し曖昧です。プロンプトに関数定義を追加することによる追加レイテンシーを測定するために、レイテンシー指向の評価を特別に開発するとよいでしょう。しかし、一部のAPIでは、少なくとも一部の時間において、ツール使用が有効になっている場合、関数が実際に呼び出されるかどうかにかかわらず、中央値TTFTが高くなることは明らかです。
- あなたの関数が遅い可能性があります!レガシーバックエンドシステムとインターフェースしている場合、関数が戻るまでに長い時間がかかる可能性があります。
ユーザーが話し終えるたびに、比較的迅速な音声フィードバックを提供する必要があります。関数呼び出しが戻るまでに時間がかかる可能性がある場合は、何が起こっているかをユーザーに伝え、待つように求める音声を出力する必要があるでしょう。

関数呼び出しを含む推論のTTFT。LLM TTFTは450msで、スループットは1秒あたり100トークンです。関数呼び出しリクエストチャンクが100トークンの場合、関数呼び出しリクエストを出力するのに1秒かかります。その後、関数を実行し、再度推論を実行します。今回は出力をストリーミングできるので、450ms後に使用できる最初のトークンが得られます。完全な推論のTTFTは1,450ms(関数自体の実行にかかる時間を含まない)です。
以下のいずれかを選択できます:
- 関数呼び出しを実行する前に常にメッセージを出力する。「Xを行っている間お待ちください…」
- ウォッチドッグタイマーを設定し、関数呼び出しループがタイマーが発火する前に完了していない場合にのみメッセージを出力する。「まだ作業中です、もう少しお待ちください…」
もちろん、両方を選択することもできます。また、長時間実行される関数呼び出し中にバックグラウンドミュージックを再生することもできます。[36]
[36] ただし、ジェパディのテーマソングは避けてください。
4.10.3 割り込みの処理
LLMは関数呼び出しリクエストメッセージと関数呼び出し応答メッセージをペアとして期待するようにトレーニングされています。
これは以下を意味します:
- すべての関数呼び出しが完了するまで、音声から音声への推論ループを停止する必要があります。以下の非同期関数呼び出しに関するメモを参照してください。
- 関数呼び出しが中断され、完了しない場合は、何かを示すコンテキストに関数呼び出し応答メッセージを入れる必要があります。
ここでのルールは、LLMが関数を呼び出した場合、コンテキストにリクエスト/応答のメッセージペアを入れる必要があるということです。
- コンテキストに未完了の関数呼び出しリクエストメッセージを入れてマルチターン会話を続けると、LLMがトレーニングされた方法と異なるコンテキストを作成することになります。(一部のAPIではこれが許可されません。)
- コンテキストにリクエスト/応答ペアをまったく入れない場合、(文脈内学習を通じて)LLMに関数を呼び出さないように教えることになります。[37]繰り返しますが、結果は予測不可能であり、おそらくあなたが望むものではありません。
[37] 論文言語モデルは少数ショット学習者であるを参照してください。
Pipecatは、関数呼び出しが開始されるたびにコンテキストにリクエスト/応答メッセージペアを挿入することで、これらのコンテキスト管理ルールに従うのを支援します。(もちろん、この動作をオーバーライドして、関数呼び出しコンテキストメッセージを直接管理することもできます。)
以下は、2つの異なる方法で設定された関数呼び出しのパターンです:完了まで実行と中断可能。
ユーザー: 1000個のウィジェットの価格を調べてください。
LLM: 1000個のウィジェットの価格を調べています。お待ちください。
関数呼び出しリクエスト: { name: "price_lookup", args: { item: "widget", quantity: 1000 } }
関数呼び出し応答: { status: IN_PROGRESS }
初期コンテキストメッセージ。関数呼び出しリクエストメッセージと関数呼び出し応答プレースホルダー。
ユーザー: 1000個のウィジェットの価格を調べてください。
関数呼び出しリクエスト: { name: "price_lookup", args: { item: "widget", quantity: 1000 } }
関数呼び出し応答: { result: { price: 12.35 } }
関数呼び出しが完了したときのコンテキスト。
ユーザー: 1000個のウィジェットの価格を調べてください。
LLM: 1000個のウィジェットの価格を調べています。お待ちください。
関数呼び出しリクエスト: { name: "price_lookup", args: { item: "widget", quantity: 1000 } }
関数呼び出し応答: { status: IN_PROGRESS }
ユーザー: 1000個の組み立て済みモジュールの価格も調べてください。
LLM: 1000個の組み立て済みモジュールの価格も調べています。お待ちください。
関数呼び出しリクエスト: { name: "price_lookup", args: { item: "pre_assembled_module", quantity: 1000 } }
関数呼び出し応答: { status: IN_PROGRESS }
プレースホルダーにより、LLMを「混乱」させることなく、関数呼び出しの実行中に会話を継続できます。
ユーザー: "1000個のウィジェットの価格を調べてください。"
LLM: "1000個のウィジェットの価格を調べています。お待ちください。"
関数呼び出しリクエスト: { name: "price_lookup", args: { item: "widget", quantity: 1000 } }
関数呼び出し応答: { status: CANCELLED }
ユーザー: 1000個の組み立て済みモジュールの価格を調べてください。
LLM: 1000個の組み立て済みモジュールの価格を調べています。お待ちください。
関数呼び出しリクエスト: { name: "price_lookup", args: { item: "pre_assembled_module", quantity: 1000 } }
関数呼び出し応答: { status: IN_PROGRESS }
関数呼び出しが中断可能として設定されている場合、関数呼び出しの進行中にユーザーが話すとキャンセルされます。
4.10.4 ストリーミングモードと関数呼び出しチャンク
音声AIエージェントのコードでは、ほぼ常に会話推論呼び出しをストリーミングモードで実行します。これにより、最初のコンテンツチャンクをできるだけ早く取得でき、音声から音声への応答レイテンシーにとって重要です。
しかし、ストリーミングモードと関数呼び出しの組み合わせは扱いにくいものです。ストリーミングは関数呼び出しチャンクには役立ちません。LLMの完全な関数呼び出しリクエストメッセージを組み立てるまで、関数を呼び出すことはできません。[38]
[38] AIフレームワークを使用している場合、フレームワークはおそらくこの複雑さをあなたから隠しています。
推論プロバイダーがAPIを進化させ続ける中で、以下のようなフィードバックを提供します:関数呼び出しチャンクをアトミックに、そしてストリーミングされたコンテンツチャンクから分離して配信するモードを提供してください。これにより、LLMプロバイダーAPIを使用するコードの複雑さが大幅に軽減されるでしょう。
4.10.5 関数呼び出しの実行方法と場所
LLMが関数呼び出しリクエストを発行した場合、どうすればよいでしょうか?以下はよく使われるパターンです:
- リクエストされた関数と同じ名前の関数呼び出しを、コード内で直接実行する。これはほとんどのLLM関数呼び出しドキュメントの例で見られるものです。
- 引数とコンテキストに基づいて、リクエストを操作にマッピングする。これは、LLMに汎用的な関数呼び出しを依頼し、コード内でそれを明確にするというパターンです。このパターンの利点は、LLMが選択できる関数の数が少ない方が、通常は関数呼び出しが上手くいくということです。[39]
- 関数呼び出しをクライアントにプロキシする。このパターンはアプリケーション(電話ではない)コンテキストで利用できます。例えば、get_location()関数を考えてみましょう。ユーザーのデバイスの現在位置が必要な場合、そのデバイス上の位置情報検索APIにフックする必要があります。
- 関数呼び出しをネットワークエンドポイントにプロキシする。これは特に企業のコンテキストで非常に有用なパターンです。内部APIと対話する関数のセットを定義し、これらの関数呼び出しをHTTPリクエストとして実行する抽象化をコード内に作成します。
[39] ここでは関数呼び出しを広範なカテゴリとして考えてください - 口語的な意味ではなく形式的な意味での関数です。ルックアップテーブルから値を返すことも、SQLクエリを実行することもできます。

関数呼び出しパターン
4.10.6 非同期関数呼び出し
関数呼び出しからすぐに戻りたくない場合もあります。関数が予測不可能な長い時間を要することがわかっている場合です。完了しない可能性もあります。あるいは、時間の経過とともにコンテキストに情報を追加できる長時間実行プロセスを開始したい場合もあるでしょう。
ユーザーがツアー中に見るかもしれないものに興味を表現できるウォーキングツアーアプリを想像してみてください。「有名な作家が住んでいた場所を通りかかったら、特にそれについて聞きたいです。」このための良いアーキテクチャの一つは、ユーザーが特定の興味を表現するたびにLLMが関数を呼び出すというものです。その関数はバックグラウンドプロセスを開始し、その興味に関連するものが見つかるとコンテキストに情報を注入します。
現在のLLM関数呼び出しを使用して、これを直接行うことはできません。関数呼び出しリクエスト/レスポンスメッセージはコンテキスト内で一緒に表示される必要があります。
そのため、次のような形の関数を定義する代わりに:
register_interest_generator(interest: string) -> Iterator[Message]
次のようなことをする必要があります:
create_interest_task_and_return_success_immediately (interest: string, context_queue_callback: Callable[Message]) -> Literal["in_progress", "canceled", "success", "failure"]
このトピックの詳細については、以下の非同期推論タスクの実行セクションを参照してください。
LLMとAPIがマルチモーダルな会話ユースケースをより適切にサポートするように進化するにつれて、非同期関数やジェネレーターとして機能する長時間実行関数などのアイデアをLLM研究者が探求することを期待しています。
4.10.7 並列および複合関数呼び出し
並列関数呼び出しとは、LLMが単一の推論応答で複数の関数呼び出しをリクエストできることを意味します。複合関数呼び出しとは、LLMが複数の関数を柔軟に連続して呼び出し、複雑な操作を実行するために関数を連鎖できることを意味します。
これらは刺激的な機能です!
しかし、これらは音声エージェントの動作の変動性も増加させます。つまり、並列および複合関数呼び出しが実際の会話で期待通りに機能しているかどうかをテストする評価とモニタリングを開発する必要があります。
並列関数呼び出しを処理すると、エージェントコードがより複雑になります。特定の用途がない限り、並列関数呼び出しを無効にすることをよく推奨しています。
複合関数呼び出しは、うまく機能すると魔法のように感じられます。複合関数呼び出しの初期の印象的な例の一つは、Claude Sonnet 3.5がファイル名とタイムスタンプに基づいてファイルからリソースをロードするために関数を連鎖させるのを見たことでした。
User: Claude, load the most recent picture I have of the Eiffel Tower.
function call request: <list_files()>
function call response: <['eiffel_tower_1735838843.jpg', 'empire_state_building_1736374013.jpg', 'eiffel_tower_1737814100.jpg', 'eiffel_tower_1737609270.jpg',
'burj_khalifa_1737348929.jpg']
function call request: <load_resource('eiffel_tower_1737814100.jpg')>
function call response: <{ 'success': 'Image loaded successfully', 'image': … }>
LLM: I have loaded an image of the Eiffel Tower. The image shows the Eiffel
Tower on a cloudy day.
LLMは2つの関数 - list_files()とload_resource() - を連鎖させて特定の指示に応答する方法を理解しています。これらの2つの関数はツールリストに記述されています。しかし、この連鎖動作はプロンプトされていません。
複合関数呼び出しは、最先端LLMの比較的新しい機能です。パフォーマンスは「でこぼこ」 - 驚くほど良いが、一貫性に欠けることがあります。
4.11. マルチモダリティ
LLMは現在、テキストに加えて音声、画像、動画を消費および生成します。
先に音声から音声へのモデルについて話しました。これらは音声を入力として受け取り、音声を出力として生成できるモデルです。
最先端モデルのマルチモーダル機能は急速に進化しています。
GPT-4o、Gemini 2.0、Claude Sonnet 3.5はすべて非常に優れたビジョン機能を持っています - これらはすべて画像を入力として受け入れます。これらのモデルでのビジョンサポートは、画像コンテンツの説明と画像に表示されるテキストの文字起こしに焦点を当てて始まりました。各リリースで機能が拡張されています。オブジェクトのカウント、バウンディングボックスの識別、画像内のオブジェクト間の関係のより良い理解など、新しいリリースで利用可能な有用な機能があります。
Gemini 2.0 Flashは、ビデオとオーディオトラックの両方を理解することを含め、ビデオ入力に対する推論を行うことができます。[40]
音声対応アプリケーションの興味深い新しいクラスの一つは、画面を「見る」ことができ、ローカルマシンやウェブブラウザでタスクを実行するのを助けるアシスタントです。多くの人々が音声駆動のウェブブラウジングのための足場を構築しています。
私たちが知っているいくつかのプログラマーは、最近では入力と同じくらい話しています。音声入力をCursorやWindsurfに接続するのは比較的簡単です。[41] また、画面キャプチャを接続して、AIプログラミングアシスタントがあなたが見ているものを正確に見ることができるようにすることも可能です - エディタ内のコード、構築中のウェブアプリのUI状態、ターミナル内のPythonスタックトレースなど。このような完全にマルチモーダルなAIプログラミングアシスタントは、このドキュメント全体で話してきた未来の一瞥のようなものです。[42]
[40] ビデオからフレームを抽出し、それらのフレームをコンテキスト内に画像として埋め込むことで、GPT-4oとClaudeの両方でビデオを処理できます。このアプローチには制限がありますが、一部の「ビデオ」ユースケースではうまく機能します。
[41] 深いAI統合とツールを備えた2つの人気の新しいプログラミングエディタ。
[42] OpenAI Dev Day 2024シンガポールでのswyxの講演、「AIエージェントのエンジニアリング」を参照してください。
現在、すべての最先端モデルは異なる組み合わせでマルチモダリティをサポートしています。
- GPT-4o(gpt-4o-2024-08-06)はテキストと画像の入力、およびテキスト出力をサポートしています。
- gpt-4o-audio-previewはテキストと音声の入力、およびテキストと音声の出力をサポートしています。(画像入力はありません。)
- Gemini 2.0 Flashはテキスト、音声、画像、ビデオの入力をサポートしていますが、出力はテキストのみです。
- OpenAIの新しい音声認識および音声合成モデルは完全に操作可能で、gpt-4o基盤上に構築されていますが、テキストと音声の変換に特化しています:gpt-4o-transcribe、gpt-4o-mini-transcribe、およびgpt-4o-mini-tts。
マルチモーダルサポートは急速に進化しており、上記のリストはすぐに古くなると予想されます!
音声AIにとって、マルチモダリティの最大の課題は、音声と画像が多くのトークンを使用し、より多くのトークンはより高いレイテンシーを意味することです。
| メディア例 | おおよそのトークン数 |
|---|---|
| テキストとしての1分間の音声 | 150 |
| 音声としての1分間の音声 | 2,000 |
| 1枚の画像 | 250 |
| 1分間のビデオ | 15,000 |
一部のアプリケーションでは、会話のレイテンシーを達成しながら多数の画像を処理することが大きなエンジニアリング課題です。会話のレイテンシーには、コンテキストを小さく保つか、ベンダー固有のキャッシングAPIに依存する必要があります。画像はコンテキストに多くのトークンを追加します。
コンピュータで常に実行され、作業ループの一部として画面を監視するパーソナルアシスタントエージェントを想像してみてください。「1時間前に電話がかかってきたときに読もうとしていたツイートがあったんだけど、その後忘れてタブを閉じてしまったんだ。あのツイートは何だったの?」と尋ねることができるかもしれません。
1時間前は約100万トークンに相当します。 モデルがコンテキスト内に100万トークンを収容できたとしても[43]、毎回そのように多くのトークンを持つマルチターン会話を行うコストとレイテンシーは法外です。
[43] こんにちは、Gemini!
ビデオをテキストとして要約し、コンテキスト内に要約のみを保持することができます。埋め込みを計算し、RAGのような検索を行うこともできます。LLMは特徴の要約と関数呼び出しを使用して複雑なRAGクエリをトリガーすることの両方に非常に優れています。しかし、これらのアプローチはどちらもエンジニアリングが複雑です。
最終的に、最大のレバレッジはコンテキストキャッシングです。すべての最先端APIプロバイダーはキャッシングのサポートを提供しています。今日のキャッシング機能はどれも、音声AIのユースケースにとってまだ完璧ではありません。マルチモーダル、マルチターンの会話ユースケースが最先端モデルをトレーニングする人々からより注目されるにつれて、キャッシングAPIが今年改善されることを期待しています。
5. 複数のAIモデルの使用
今日の本番環境の音声AIエージェントは、複数のディープラーニングモデルを組み合わせて使用しています。[44]
これまで議論してきたように、典型的な音声AI処理ループは、音声認識モデルでユーザーの声を文字起こしし、文字起こしされたテキストをLLMに渡して応答を生成し、その後テキスト音声変換ステップを実行してエージェントの音声出力を生成します。
さらに、今日の多くの本番環境の音声エージェントは、複雑で多様な方法で複数のモデルを使用しています。
[44] OpenAIとGoogleのベータ版音声から音声へのAPIでさえ、ターン検出を実装するために専用のVADとノイズ削減モデルを使用しています。
5.1. 複数の微調整モデルの使用
ほとんどの音声AIエージェントは、OpenAIやGoogle(そして時にはAnthropicやMeta)からの最先端[45]モデルを使用しています。最新かつ最高性能のモデルを使用することは重要です。なぜなら、音声AIワークフローは一般的にモデル能力のでこぼこフロンティア[46]の端にあるからです。音声エージェントは複雑な指示に従い、人々と自然な方法でオープンエンドな会話に参加し、関数やツールを確実に使用する必要があります。
[45] SOTA — 最先端 — は広く使用されているAIエンジニアリング用語で、大まかに「主要なAI研究所からの最新の大規模モデル」を意味します。
しかし、一部の特殊なユースケースでは、会話の異なる状態に合わせてモデルを微調整することが理にかなっている場合があります。微調整されたモデルは、特定のタスクで同等(またはそれ以上)のパフォーマンスを発揮しながら、大規模モデルよりも小さく、高速で、実行コストが低くなる可能性があります。
非常に大きな産業用供給カタログからの部品注文を支援するエージェントを想像してみてください。このタスクのために、異なるカテゴリに焦点を当てた複数の異なるモデルをトレーニングするかもしれません:プラスチック材料、金属材料、ファスナー、配管、電気、安全装備など。
[46] ウォートン大学の教授イーサン・モリックは、最先端モデル能力の複雑なエッジゾーン — 時には驚くほど優れ、時にはイライラするほど悪い — を表現するために「でこぼこフロンティア」という用語を作りました。
微調整されたモデルは一般的に2つの重要なカテゴリで「学習」することができます:
- 埋め込まれた知識 — モデルは事実を学習できます。
- 応答パターン — モデルは特定の方法でデータを変換することを学習できます。これには会話パターンとフローの学習も含まれます。
私たちの仮想的な産業用供給会社は広範な生データを持っています:
- カタログ内のすべての部品に関するデータシート、メーカーの推奨事項、価格、内部データで構成される非常に大きな知識ベース。
- テキストチャットログ、メールチェーン、人間のサポートエージェントとの文字起こしされた電話会話。

特定の会話トピックのための微調整モデルの使用。様々なアーキテクチャアプローチが可能です。この例では、各会話ターンの始めにルーターLLMが完全なコンテキストを分類します。
この生データを微調整モデル用のデータセットに変換することは大きな仕事ですが、実行可能です。必要なデータクリーニング、データセット作成、モデルトレーニング、モデル評価はすべてよく理解されている問題です。
重要な注意点:微調整に直接飛びつかないでください — プロンプトエンジニアリングから始めてください。
プロンプティングはほぼ常に微調整と同じタスク結果を達成できます。微調整の利点は、より小さなモデルを使用できることであり、これはより高速な推論とより低いコストに変換できます。[47]
プロンプティングを使用すると、微調整よりもはるかに簡単に始めることができ、はるかに迅速に反復することができます。[48]
異なる会話状態に対して異なるモデルを使用する方法を最初に探索する際、プロンプトを小さな「モデル」と考えてください。大きなコンテキスト固有のプロンプトを作成することで、LLMに何をすべきかを教えています。
- 埋め込まれた知識については、知識ベースから情報を引き出し、検索結果を効果的なプロンプトにまとめることができる検索機能を実装します。これについての詳細は、以下のRAGとメモリセクションを参照してください。
- 応答パターンについては、モデルが異なる質問にどのように応答することを期待するかの例を埋め込みます。時には、ほんの数例で十分です。時には、多くの例 — 100以上 — が必要になるでしょう。
[47] プロンプティングと微調整の深い比較に興味がある場合は、これら2つの古典的な論文を参照してください:「言語モデルは少数ショット学習者である(Language Models Are Few-shot Learners)」と「少数ショット学習の包括的調査(A Comprehensive Survey of Few-shot Learning)」。
[48] 古典的なエンジニアリングのアドバイスに従いましょう:まず動作させ、次に高速化し、最後に低コスト化する。プロンプトエンジニアリングから微調整への移行を考えるのは、「高速化」のプロセスの途中からにしましょう(もし必要であれば)。
5.2. 非同期推論タスクの実行
時には、比較的長い時間がかかるタスクにLLMを使用したい場合があります。私たちのコア会話ループでは、約1秒(またはそれ以下)の応答時間を目指していることを覚えておいてください。タスクが数秒以上かかる場合、2つの選択肢があります:
- ユーザーに何が起きているかを伝え、待ってもらう。「少々お待ちください、調べています…」
- より長いタスクを非同期で実行し、バックグラウンドで処理している間も会話を続ける。「調べておきます。その間に他にご質問はありますか?」
非同期で推論タスクを実行する場合、そのタスク専用に異なるLLMを使用することもできます(コア会話ループから切り離されているため)。音声応答には許容できないほど遅いLLMや、特定のタスク用に微調整されたLLMを使用することもできます。
非同期推論タスクの例:
- コンテンツの「ガードレール」の実装(コンテンツガードレールセクションを参照)。
- 画像の生成。
- サンドボックスで実行するコードの生成。
推論モデル[49]における最近の驚くべき進歩により、LLMに依頼できることの範囲が拡大しています。ただし、これらのモデルは音声AI会話ループには使用できません。なぜなら、使用可能な出力を生成する前に、「思考」トークンの生成に多くの時間を費やすことがあるからです。しかし、推論モデルをマルチモデル音声AIアーキテクチャの非同期部分として使用することは効果的です。
[49] 推論モデルの例としては、DeepSeek R1、Gemini Flash 2.0 Thinking、OpenAI o3-miniなどがあります。
非同期推論は通常、LLM関数呼び出しによってトリガーされます。シンプルなアプローチは、2つの関数を定義することです。
perform_async_inference()— これはLLMが長時間実行の推論タスクを実行すべきだと判断したときに呼び出されます。これらは複数定義することができます。非同期タスクを開始し、すぐに基本的なタスク開始成功応答を返す必要があることに注意してください。これにより、関数呼び出しのリクエストと応答メッセージがコンテキスト内で正しく順序付けられます。[50]queue_async_context_insertion()— これは非同期推論が完了したときにオーケストレーション層から呼び出されます。ここでの難しい点は、コンテキストに結果を挿入する方法が、実行しようとしていることと、使用しているLLM/APIが許可していることに依存することです。一つのアプローチは、進行中の会話ターンの終了(すべての関数呼び出しの完了を含む)まで待ち、非同期推論結果を特別に作成されたユーザーメッセージに入れ、その後別の会話ターンを実行することです。
[50] 非同期関数呼び出しを参照してください。
5.3. コンテンツガードレール
音声AIエージェントには、一部のユースケースで大きな問題を引き起こす脆弱性がいくつかあります。
- プロンプトインジェクション
- ハルシネーション(幻覚)
- 古い知識
- 不適切または安全でないコンテンツの生成
コンテンツガードレールは、これらのいずれかを検出しようとするコードの一般的な用語です — 偶発的および悪意のあるプロンプトインジェクションからLLMを保護し、悪いLLM出力がユーザーに送信される前にそれをキャッチします。
ガードレールに特定のモデル(または複数のモデル)を使用することには、いくつかの潜在的な利点があります:
- 小さなモデルはガードレールと安全性監視に適している場合があります。問題のあるコンテンツの識別は比較的専門的なタスクです。(実際、特にプロンプトインジェクション緩和については、完全に一般的な方法でプロンプトできるモデルを必ずしも望まないかもしれません。)
- ガードレール作業に異なるモデルを使用する利点は、少なくとも理論上は、メインモデルとまったく同じ弱点を持たないことです。
いくつかのオープンソースエージェントフレームワークにはガードレールコンポーネントがあります。
- llama-guardはMetaのllama-stackの一部です
- NeMO GuardrailsはLLMベースの会話アプリケーションにプログラム可能なガードレールを追加するためのオープンソースツールキットです

NVIDIAのNeMo Guardrailsフレームワークでサポートされている5種類のガードレール。図はNeMo Guardrailsのドキュメントから。
これらのフレームワークはどちらもテキストチャットを念頭に設計されており、音声AIではありません。しかし、どちらも有用なアイデアと抽象化を持っており、ガードレール、安全性、コンテンツモデレーションについて考えている場合は検討する価値があります。
LLMは1年前と比べて、これらすべての問題を回避することが格段に上手くなっていることは注目に値します。
一般的なハルシネーションは、大手研究所の最新モデルではもはや大きな問題ではありません。現在、私たちが定期的に見るハルシネーションは2つのカテゴリーだけです。
- LLMが関数を呼び出す「ふり」をするが、実際には呼び出さない場合。これはプロンプティングで修正可能です。プロンプトでこれが発生しないことを確認するには、良い評価が必要です。評価でハルシネーションが見られた場合、それが見られなくなるまでプロンプトを繰り返し改良します。(マルチターン会話はLLMの関数呼び出し能力を本当にテストするので、評価は実世界のマルチターン会話を反映する必要があることを覚えておいてください。)
- ウェブ検索を期待しているときにLLMがハルシネーションを起こす場合。組み込みの検索接地は、LLM APIの比較的新しい機能です。LLMが検索を実行するかどうかは、まだ少し予測不可能です。検索しない場合、重みに埋め込まれた(古い)知識で応答するか、ハルシネーションを起こす可能性があります。関数呼び出しのハルシネーションとは異なり、これはプロンプティングで特に修正しやすいものではありません。しかし、検索が実際に実行されたかどうかを知ることは簡単です。そのため、アプリケーションUIにその情報を表示したり、音声会話に注入したりすることができます。アプリがウェブ検索に依存している場合、これを行うことは良いアイデアです。「検索した」か「検索しなかった」かの区別をユーザーから隠すよりも、ユーザーに理解して対処してもらう方が良いです。肯定的な面では、検索接地がうまく機能すると、古い知識の問題をほぼ排除できます。
主要な研究所からのすべてのAPIには、非常に優れたコンテンツ安全フィルターがあります。
プロンプトインジェクション緩和も1年前よりはるかに良くなっていますが、LLMが新しい機能を獲得するにつれて、潜在的なプロンプトインジェクション攻撃の表面積が拡大しています。例えば、画像内のテキストからのプロンプトインジェクションが現在問題になっています。
非常に一般的なガイドラインとして:今日の音声AIユースケースでは、通常のユーザー行動によって引き起こされる偶発的なプロンプトインジェクションが発生する可能性は低いです。しかし、ユーザー入力のみを通じて、システム指示を覆すような方法でLLMの動作を誘導することは間違いなく可能です。これを念頭に置いてエージェントをテストすることが重要です。特に、バックエンドシステムにアクセスする関数へのLLM生成入力を消毒し、クロスチェックすることが非常に重要です。
5.4. 単一推論アクションの実行
AIエンジニアにとって、LLMの活用方法を学ぶことは継続的なプロセスです。そのプロセスの一部は、これらの新しいツールについての考え方の精神的な転換です。LLMを最初に使い始めたとき、私たちのほとんどは言語モデルは何が独自にできるのか?というレンズを通してそれらを考えていました。しかし、LLMは汎用ツールです。非常に幅広い情報処理タスクに優れています。
音声エージェントのコンテキストでは、LLM推論を実行するためのコードパスが常に設定されています。LLMをコア会話ループにのみ使用することに制限する必要はありません。
例えば:
- 正規表現を使用する場合、代わりにプロンプトを書くことができる可能性があります。
- LLM出力の後処理は多くの場合有用です。例えば、UIに表示するためのテキストと対話型会話用の音声という2つの形式で出力を生成したい場合があります。会話LLMに整形されたマークダウンテキストを生成するようプロンプトし、その後LLMに再度プロンプトして、音声生成用にテキストを短縮し再フォーマットすることができます。[51]
- 再帰は強力です。[52] LLMにリストを生成させ、その後LLMを再度呼び出してリストの各要素に対して操作を実行するなどのことができます。
- マルチターン会話を要約したいことがよくあります。LLMは素晴らしく、操作可能な要約ツールです。これについては、以下のスクリプティングと指示の遵守セクションで詳しく説明します。
[51] LLM出力の後処理に関しては、上記のコンテンツガードレールセクションも参照してください。
[52] 私たちはプログラマーなので、もちろん … — 編集者注
これらの新しいコードパターンの多くは、言語モデルが自分自身、または別の言語モデルをツールとして使用しているように見えます。
これは非常に強力なアイデアであり、2025年には多くの人々がこれに取り組むことを期待しています。エージェントフレームワークはこれをライブラリレベルのAPIにサポートを組み込むことができます。モデルは、関数を呼び出しコード実行を行うように訓練するのとほぼ同様の方法で、再帰的に推論を実行するように訓練することができます。
5.5. 自己改善システムに向けて
APIを通じて最先端の「モデル」にアクセスするとき、私たちは単一のアーティファクトにアクセスしているわけではありません。APIの背後にあるシステムは、様々なルーティング、多段階処理、分散システム技術を使用して、高速で柔軟、信頼性が高く、非常に大規模に推論を実行します。これらのシステムは常に調整されています。重みが更新されます。低レベルの推論実装は常に効率化されています。システムアーキテクチャは進化しています。
大手研究所は、ユーザーがAPIをどのように使用するかと、推論やその他の機能をどのように実装するかの間のフィードバックループを継続的に短縮しています。
これらの常に高速化するフィードバックループは、現在起きている驚くべきマクロレベルのAI進歩の大きな部分です。
これからインスピレーションを得て、エージェントレベルのコードにおけるミクロレベルのフィードバックループはどのようなものになるでしょうか?会話中にエージェントのパフォーマンスを向上させる特定の足場を構築できるでしょうか?
- エージェントがユーザーの発話が終わる前に割り込む頻度を監視し、VADタイムアウトなどのパラメータを動的に調整する。
- ユーザーがエージェントに割り込む頻度を監視し、LLMの応答の長さを動的に調整する。
- ユーザーが会話を理解するのに苦労していることを示すパターンを探す — おそらくユーザーはネイティブスピーカーではない。会話スタイルを調整したり、言語の切り替えを提案したりする。
他にどんなアイデアが思いつきますか?
ユーザー: MNIの最近の業績はどうですか?
エージェント: マイアミ・ドルフィンズは昨日の試合で21対3で勝ち、
レギュラーシーズン残り2試合でAFCイーストをリードしています。
ユーザー: いいえ、MNIという株のことです。
エージェント: 申し訳ありません!MNIの株価パフォーマンスについて
お尋ねでしたね。MNIはマクラッチー・カンパニーの
ティッカーシンボルです…
この時点から、モデルは音素または文字起こしされたテキストを
「マイアミ」ではなく「MNI」として解釈する傾向を持ちます。
マルチターンセッション中にユーザーフィードバックに基づいて動作を調整するLLMの例(文脈内学習)
6. スクリプティングと指示の遵守
1年前は、自然な人間のレイテンシーでオープンエンドの会話ができる音声エージェントを構築できるというだけでワクワクしていました。
現在、私たちは複雑な実世界のタスクを実行するために音声AIエージェントを展開しています。今日のユースケースでは、セッション中に特定の目標に集中するようLLMに指示する必要があります。多くの場合、LLMに特定の順序でサブタスクを実行させる必要があります。
例えば、医療患者の受付ワークフローでは、エージェントに以下のことを望みます:
- 他の何かをする前に患者のIDを確認する。
- 患者が現在服用している薬を必ず尋ねる。
- 患者が薬Xを服用していると言った場合、特定のフォローアップ質問をする。
- など…
ステップバイステップのワークフローを作成することをスクリプティングと呼びます。音声AI開発の過去1年間からの教訓の一つは、プロンプトエンジニアリングだけでスクリプティングの信頼性を達成するのは難しいということです。
単一のプロンプトに詰め込むことができる詳細には限界があります。同様に、マルチターン会話でコンテキストが増えるにつれて、LLMは追跡する情報がますます多くなり、指示遵守の精度が低下します。
多くの音声AI開発者は、複雑なワークフローを構築するためにステートマシンアプローチに移行しています。LLMを導くための長く詳細なシステム指示を書く代わりに、一連の状態を定義することができます。各状態は:
- システム指示とツールリスト。
- 会話コンテキスト。
- 現在の状態から別の状態への1つ以上の出口。
各状態遷移は以下の機会です:
- システム指示とツールリストを更新する。
- コンテキストを要約または修正する。[53]
[53] 通常、コンテキスト要約を実行するためにLLM推論呼び出しを行います。:-)
ステートマシンアプローチがうまく機能するのは、より短く、より焦点を絞ったシステム指示、ツールリスト、コンテキストがLLMの指示遵守を大幅に向上させるからです。
課題は、一方ではLLMのオープンエンドで自然な会話を行う能力を活用し、他方では仕事の重要な部分を確実に実行させるという、適切なバランスを見つけることです。
Pipecat FlowsはPipecatの上に構築されたライブラリで、開発者がワークフローステートマシンを作成するのを支援します。
状態図はJSONとして表現され、Pipecatプロセスにロードできます。これらのJSON状態図を作成するためのグラフィカルエディタがあります。
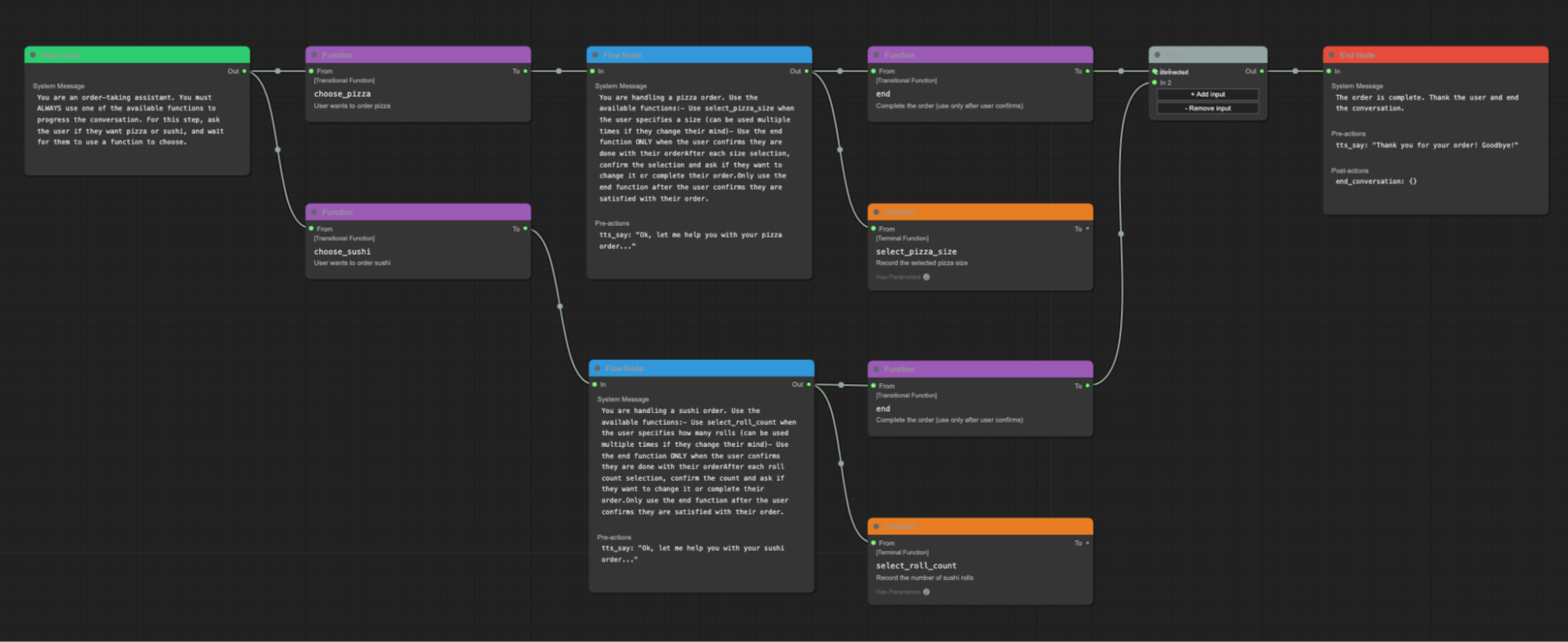
Pipecat Flowsグラフィカルエディタ
Pipecat Flowsとステートマシンは現在、多くの開発者に採用されています。しかし、複雑なワークフローのための抽象化を構築する他の興味深い方法もあります。
AIの研究開発の活発な分野の一つはマルチエージェントシステムです。ワークフローを横断する一連の状態としてではなく、マルチエージェントシステムとして考えることもできます。
Pipecatのコアアーキテクチャコンポーネントの一つは並列パイプラインです。並列パイプラインでは、処理グラフを通過するデータを分割し、2回(またはそれ以上)操作することができます。データをブロックしてフィルタリングすることができます。多くの並列パイプラインを定義することができます。ワークフローをゲート制御された調整された並列パイプラインのセットとして考えることもできます。
音声AIツールの急速な進化は刺激的であり、これらの新しい種類のプログラムを構築する最良の方法を見つけるのがまだ初期段階であることを強調しています。
7. 音声AI評価
非常に重要なツールの一つは評価(eval)です。
評価は機械学習用語で、システムの能力を評価し、その品質を判断するためのツールまたはプロセスを指します。
7.1. 音声AI評価はソフトウェアユニットテストとは異なる
伝統的なソフトウェアエンジニアリングのバックグラウンドから来ている場合、テストを(ほとんど)決定論的な演習として考えることに慣れています。
音声AIには、従来のソフトウェアエンジニアリングとは異なるテストが必要です。音声AIの出力は非決定的です。音声AIをテストするための入力は、複雑で分岐し、複数のターンを持つ会話です。
特定の入力が特定の出力を生成する(f(x) = y)ことをテストする代わりに、確率的な評価を実行する必要があります - 特定のタイプのイベントがどれくらいの頻度で発生するかを確認するために多くのテスト実行を行います。[54] 一部のテストでは、特定のケースのクラスを10回中8回正しく処理できれば許容されますが、他のテストでは精度が10回中9.99回必要です。
[54] ユーザーリクエストが満たされた、エージェントがユーザーを中断した、エージェントが話題から外れたなど
1つの入力だけでなく、すべてのユーザー応答という多くの入力があります。これにより、ユーザーの行動をシミュレートしようとせずに音声AIアプリケーションをテストすることは非常に困難になります。
Finally, voice AI tests have non-binary results and will rarely yield a definitive ✅ or ❌ like traditional unit tests do. Instead, you will need to review results and decide on tradeoffs.
7.2. 失敗モード
音声AIアプリケーションには特有の形態と失敗モードがあり、それらが評価の設計と実行方法に影響を与えます。レイテンシーは非常に重要です(テキストモードのシステムでは許容されるレイテンシーでも、音声システムでは失敗となります)。また、マルチモーダルであるため(例えば、パフォーマンスの低下はLLMの動作ではなく、TTSの不安定さが原因かもしれません)。
現在、頻繁に課題となる領域には以下のようなものがあります:
- 最初の発話までの時間とエージェントの応答時間のレイテンシー
- 文字起こしエラー
- 住所、メール、名前、電話番号の理解と音声化
- 中断
7.3. 評価戦略の構築
基本的な評価プロセスは、プロンプトとテストケースを含むスプレッドシートのように単純なものでも構いません。
一般的なアプローチの一つは、新しいモデルをテストしたり、システムの主要部分を変更したりするたびに各プロンプトを実行し、LLMを使用して応答が期待されるパラメータの範囲内に収まっているかどうかを判断することです。
基本的な評価を持つことは、まったく評価を持たないよりもはるかに良いことです。しかし、評価に投資すること—本当に良い評価を持つこと—は、規模で運用し始めると非常に重要になります。
音声AI評価のための高度なツールを提供する評価プラットフォームはまだ登場し始めたばかりです。Covalは音声およびチャットエージェントのテストと評価ツールを構築しているスタートアップです。Covalのシミュレーション指向のアプローチは、音声AIエコシステムにおける評価の進化に強い影響を与えています。
Coval評価プラットフォームUIのスクリーンショット
Covalやその他の評価プラットフォームは以下のような点で役立ちます:
- プロンプトの反復。
- 音声、ワークフロー、関数呼び出し、会話の意味的評価のための既製のメトリクス。
- 問題領域の改善(例えば、中断の処理を向上させるなど)。
- 回帰テスト(ある問題領域を修正したときに、以前に解決した他の問題領域に回帰を引き起こさないことを確認するため)。
- 開発者による変更や、ユーザーコホート間での時間経過に伴うパフォーマンスの変化の追跡。
8. 電話インフラストラクチャとの統合
現在、最も急速に成長している音声AIのユースケースの多くは電話通話に関連しています。 AI音声エージェントは今日、電話に応答し、大規模に電話をかけています。
これらの一部は従来のコールセンターで行われています。コールセンターは主に音声AIを「デフレクション率」—自動化によって処理できる通話の割合—を向上させることができる技術と見なしています。これにより、音声AI採用のROI(投資収益率)が明確になります。LLMの1分あたりのコストが人間のエージェントの1分あたりのコストよりも安ければ、購入の決断は簡単です。[55]
[55] もちろん、AIエージェントのパフォーマンスが良いことを前提としています。現在、多様なカスタマーサポートのユースケースでは、それは実現されています。
しかし、単純なROI計算を超えて、採用を加速させる興味深いことがいくつか起きています。
音声AIエージェントは人間のスタッフとは異なる方法でスケーラブルです。音声AIを導入すると、高負荷期間中の待ち時間が短縮されます(その結果、顧客満足度スコアが直接向上します)。
また、LLMはより良いツールを提供されているため、人間のエージェントよりも優れた仕事をすることがあります。多くのカスタマーサポート状況では、人間のエージェントは複数のレガシーバックエンドシステムを扱わなければなりません。タイムリーに情報を見つけることが課題となることがあります。同じ状況に音声AIを導入する場合、これらのレガシーシステムへのAPIレベルのアクセスを構築する必要があります。新しいLLMとAPIの層が音声AIへの技術移行を可能にしています。
生成AIが今後数年間でコールセンターの風景を完全に再形成することは明らかです。
コールセンター以外でも、音声AIは小規模ビジネスが電話に対応する方法や、情報発見と調整のために電話を使用する方法を変えています。私たちは毎日、あらゆるビジネス分野向けの特化したAI電話ソリューションを構築しているスタートアップと話をしています。
この分野の人々はよく、まもなく人間は電話をかけたり受けたりしなくなり、すべての電話はAI対AIになるだろうと冗談を言います。私たちが見ている傾向線から判断すると、これには真実があります!
音声AIの電話に興味がある場合、いくつかの頭字語と一般的な概念に精通しておくべきです。
- PSTNは公衆交換電話網(Public Switched Telephone Network)です。電話番号を持つ実際の電話と対話する必要がある場合は、PSTNプラットフォームと連携する必要があります。Twilioはほとんどすべての開発者が聞いたことのあるPSTNプラットフォームです。
- SIPはIP電話に使用される特定のプロトコルですが、一般的な意味ではSIPはシステム間の電話相互接続を指します。例えば、コールセンターの技術スタックとインターフェースする場合は、SIPを使用する必要があります。SIPプロバイダーと連携するか、独自のSIPサーバーをホストすることができます。
- DTMFトーンは電話メニューをナビゲートするために使用されるキープレス音です。音声エージェントは実際の電話システムと対話するためにDTMFトーンを送信できる必要があります。LLMは電話ツリーの処理が得意です。少しのプロンプトエンジニアリングとDTMFトーンを送信する関数を定義するだけで済みます。
- 音声エージェントはしばしば通話転送を実行する必要があります。単純な転送では、音声AIは通話転送をトリガーする関数を呼び出してセッションを終了します。[56] ウォームトランスファーは、エージェントが発信者を転送する前に互いに会話する、あるエージェントから別のエージェントへの引き継ぎです。音声AIエージェントは人間と同様にウォームトランスファーを行うことができます。音声エージェントは最初に人間の発信者と話し、次に人間の発信者を保留にして通話に参加する新しい人間のエージェントと会話し、その後、人間の発信者を人間のエージェントに接続します。
[56] 実際の転送操作は、電話プラットフォームへのAPI呼び出しやSIP REFERアクションかもしれません。
9. RAGとメモリ
音声AIエージェントはしばしば外部システムから情報にアクセスします。例えば、以下のようなことが必要かもしれません:
- ユーザーに関する情報をLLMシステム指示に組み込む。
- 以前の会話履歴を取得する。
- ナレッジベースで情報を検索する。
- ウェブ検索を実行する。
- リアルタイムの在庫や注文状況を確認する。
これらはすべてRAG – 検索拡張生成(Retrieval Augmented Generation)のカテゴリに分類されます。RAGは情報検索とLLMプロンプティングを組み合わせる一般的なAIエンジニアリング用語です。
音声エージェントの「最もシンプルなRAG」は、会話が始まる前にユーザーに関する情報を検索し、その情報をLLMシステム指示にマージすることです。
user_info = fetch_user_info(user_id)
system_prompt_base = "You are a voice AI assistant..."
system_prompt = (
system_prompt_base
+ f"""
患者の名前は{user_info["name"]}です。
患者は{user_info["age"]}歳です。
患者には以下の病歴があります:{user_info["summarized_history"]}。
"""
)
シンプルなRAG – セッションの開始時に検索を実行する
RAGは深いトピックであり、急速に変化している領域です。[57] 技術は、基本的な検索と文字列補間を使用する上記の比較的シンプルなアプローチから、埋め込みとベクトルデータベースを使用して非常に大量の半構造化データを整理するシステムまで多岐にわたります。
[57] うーん。これは最近の生成AIの他のすべての領域と同じように聞こえますね。
多くの場合、80/20アプローチで非常に長い道のりを進むことができます。既存のナレッジベースがある場合は、すでに持っているAPIを使用してください。検索結果を会話コンテキストに挿入するためのいくつかの異なるフォーマットをテストできるシンプルな評価を作成します。本番環境にデプロイし、実際のユーザーとの相互作用でどれだけうまく機能するかを監視します。
async def query_order_system(function_name, tool_call_id, args, llm, context, result_callback):
"まず音声フレームをプッシュします。これはLLMの応答に時間がかかる可能性がある場合に便利です。"
await llm.push_frame(TTSSpeakFrame("その注文を調べている間、少々お待ちください。"))
query_result = order_system.get(args["query"])
await result_callback({
"info": json.dumps({
"lookup_success": True,
"order_status": query_result["order_status"],
"delivery_date": query_result["delivery_date"],
})
})
llm.register_function("query_order_system", query_order_system)
セッション中のRAG。情報検索が必要な場合にLLMが呼び出す関数を定義します。この例では、システムが応答するのに数秒かかることをユーザーに知らせるために、あらかじめ設定された音声フレーズも発します。
いつものように、レイテンシーは非音声AIシステムよりも音声AIでより大きな課題です。LLMが関数呼び出しリクエストを行うと、追加の推論呼び出しがレイテンシーを増加させます。外部システムでの情報検索も遅い場合があります。RAG検索を実行する前に単純な音声出力をトリガーして、作業が進行中であることをユーザーに知らせることがよくあります。
より広い意味では、セッション間のメモリは有用な機能です。あなたが話すすべてのことを覚えておく必要がある音声AI個人アシスタントを想像してみてください。一般的なアプローチは2つあります:
- 各会話を永続的なストレージに保存します。コンテキストに会話をロードするためのいくつかのアプローチをテストします。例えば、個人アシスタントのユースケースでうまく機能する戦略:エージェント起動時に最新の会話を完全にロードし、最新のN個の会話の要約をロードし、LLMが必要に応じて古い会話を動的にロードするために使用できる検索関数を定義します。
- 会話履歴の各メッセージをメッセージグラフに関するメタデータとともに個別にデータベースに保存します。すべてのメッセージにインデックスを付けます(おそらく意味的な埋め込みを使用して)。これにより、分岐する会話履歴を動的に構築することができます。アプリが画像入力(LLMビジョン)を多用する場合は、これを行いたいかもしれません。[58] 画像はコンテキスト空間を多く占めます!このアプローチでは、分岐UIを構築することもできます。これはAIアプリデザイナーがちょうど探索し始めている方向です。
[58] マルチモダリティを参照してください。
10. ホスティングとスケーリング
音声AIアプリケーションには、ウェブアプリフロントエンド、APIエンドポイント、その他のバックエンド要素など、いくつかの従来のアプリケーションコンポーネントがあります。しかし、エージェントプロセス自体は従来のアプリコンポーネントとは十分に異なるため、音声AIのデプロイとスケーリングには独自の課題があります。
- 音声AIエージェントの会話ループは通常、長時間実行されるプロセスです(単一の応答が生成されると終了するリクエスト/レスポンス関数ではありません)。
- 音声エージェントはリアルタイムで音声をストリーミングします。ストリーミングを停滞させるものは音声の不具合を引き起こす可能性があります(共有仮想マシンでのCPUスパイク、わずか10msでも音声スレッドの実行をブロックするプログラムフローなど)。
- 音声エージェントは通常、WebSocketまたはWebRTC接続が必要です。クラウドサービスのネットワークゲートウェイとルーティング製品は、HTTPほどWebSocketをサポートしていません。多くの場合、UDPをまったくサポートしていません(UDPはWebRTCに必要です)。
これらすべての理由から、音声AIにはAWS LambdaやGoogle Cloud Runなどのサーバーレスフレームワークを使用することは一般的に不可能です。
現在の音声AIエージェントをデプロイするためのベストプラクティスは次のとおりです:
- プロトタイピングフェーズを過ぎたら、エージェントをデプロイするためのDocker(または同様の)コンテナを構築する軽量ツールの作成にエンジニアリング時間を投資します。
- コンテナを選択したコンピューティングプラットフォームにプッシュします。シンプルなデプロイメントの場合は、固定数の仮想マシンを実行し続けることができます。しかし、ある時点で、自動スケーリング、新バージョンの適切なデプロイ、優れたサービスディスカバリとフェイルオーバーの実装、その他の大規模なDevOps要件の構築のために、プラットフォームのツールに接続したくなるでしょう。
- Kubernetesは現在、コンテナ、デプロイメント、スケーリングを管理するための標準です。Kubernetesには急な学習曲線がありますが、すべての主要なクラウドプラットフォームでサポートされています。Kubernetesには非常に大きなエコシステムがあります。
- ソフトウェアアップデートをデプロイする場合、セッションが終了するまで既存の接続を維持できる長いドレイン時間を設定する必要があります。これはKubernetesでは特に難しくありませんが、詳細はk8sエンジンとバージョンによって異なります。
- コールドスタートは音声AIエージェントにとって問題です。なぜなら、接続時間の速さが重要だからです。アイドル状態のエージェントプールを維持することは、長いコールドスタートを避ける最も簡単な方法です。ワークロードがローカルで大きなモデルを実行する必要がない場合、一般的にあまり努力せずに高速なコンテナコールドスタートを設計することができます。[59]
仮想マシンの仕様とコンテナのパッキングは、初めて本番環境にデプロイする際によく人々を躓かせます。エージェントに必要な仕様は、使用するライブラリとエージェントプロセス内で行うCPU集約型の作業の量によって異なります。良い経験則は、仮想マシンのCPUごとに1つのエージェントを実行し、開発マシンでエージェントプロセスが消費する最大RAM量の2倍を用意することから始めることです。[60]
[59] 大きなモデルをローカルで実行している場合、コールドスタートに関するアドバイスはこのガイドの範囲外です。GPUとコンテナの最適化の専門家でない場合は、おそらく(少なくとも必要なツールを開発するコストを償却するのに十分な大規模な運用をするまでは)その学習曲線を上るよりも、専門家を見つけた方が良いでしょう。
[60] コンテナランタイムがアイドル状態のCPUで新しいエージェントプロセスを開始していることを確認してください。これは必ずしもk8sのデフォルトではありません。
11. 2025年に来るもの
AIエンジニアリングの成長について言えば、音声AIは2024年に大きく成長し、2025年もこの傾向が続くと予想しています。
この拡大する関心と採用により、いくつかの重要な中核領域で継続的な進歩が生まれるでしょう:- すべてのモデル構築者とサービスプロバイダーからのさらなるレイテンシー最適化。長い間、サービスを実装するほとんどの人と公開されたベンチマークのほとんどは、レイテンシーよりもスループットに焦点を当てていました。音声AIでは、1秒あたりのトークン数よりも最初のトークンまでの時間をはるかに重視します。
- モデルとAPIにおけるすべての非テキストモダリティの完全な統合に向けた進歩。
- テストと評価ツールにおけるより多くの音声特化機能。
- リアルタイムマルチモーダルユースケースのニーズをサポートするコンテキストキャッシングAPI。
- 複数のプロバイダーからの新しい音声エージェントプラットフォーム。
- 複数のプロバイダーからの音声から音声へのモデルAPI。
音声AI分野の4人の専門家による2025年についての率直な意見に興味がある場合は、1月のサンフランシスコ音声AIミートアップのパネルの録画の54:05にスキップしてください。Karan Goel、Niamh Gavin、Shrestha Basu-Mallick、Swyxはすべて、来年に見られるであろうものについての予測を提供しました:ユニバーサルメモリ、ハリウッドでのAI、モデル模倣からモデル理解への移行、そしてロボティクスに関する反対意見。
楽しい一年になるでしょう。
貢献者
主執筆者
Kwindla Hultman Kramer
貢献執筆者[61]
Aleix Conchillo Flaqué, Mark Backman, Moishe Lettvin, Kwindla Hultman Kramer, Jon Taylor, Vaibhav159, chadbailey59, allenmylath, Filipi Fuchter, TomTom101, Mert Sefa AKGUN, marcus-daily, vipyne, Adrian Cowham, Lewis Wolfgang, Filipi da Silva Fuchter, Vanessa Pyne, Chad Bailey, Dominic, joachimchauvet, Jin Kim, Sharvil Nanavati, sahil suman, James Hush, Paul Kompfner, Mattie Ruth, Rafal Skorski, mattie ruth backman, Liza, Waleed, kompfner, Aashraya, Allenmylath, Ankur Duggal, Brian Hill, Joe Garlick, Kunal Shah, Angelo Giacco, Dominic Stewart, Maxim Makatchev, antonyesk601, balalo, daniil5701133, nulyang, Adi Pradhan, Cheng Hao, Christian Stuff, Cyril S., DamienDeepgram, Dan Goodman, Danny D. Leybzon, Eric Deng, Greg Schwartz, JeevanReddy, Kevin Oury, Louis Jordan, Moof Soup, Nasr Maswood, Nathan Straub, Paul Vilchez, RonakAgarwalVani, Sahil Suman, Sameer Vohra, Soof Golan, Vaibhav-Lodha, Yash Narayan, duyalei, eddieoz, mercuryyy, rahulunair, roey, vatsal, vengadanathan srinivasan, weedge, wtlow003, zzz
Design
Sascha Mombartz
Akhil K G
[61] GitHub usernames, github.com/pipecat-ai/pipecat/graphs/contributors